Spredning / Foranstaltninger i form af Spredning: Definition
Statistik Definitioner > Dispersion
Hvad er Spredning?
Dispersion i statistik er en måde at beskrive, hvordan spredt ud et sæt data er. Når et datasæt har en stor værdi, er værdierne i sættet bredt spredt; når det er lille, er elementerne i sættet tæt grupperet., Meget dybest set, er dette sæt af data har en lille værdi:
1, 2, 2, 3, 3, 4
…og dette sæt har en bredere et:
0, 1, 20, 30, 40, 100
udbredelsen af et datasæt, kan beskrives ved en række beskrivende statistik, herunder varians, standardafvigelse, og kvartilafstand. Spredning kan også vises i grafer: dot plots, bo .plots, og stilk og blad plots har en større afstand med prøver, der har en større spredning og omvendt.
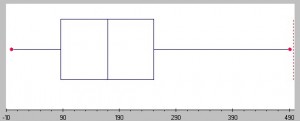
jo større boksen er, jo mere dispersion i et sæt data., Billede: Seton Hall University
målinger af Dispersion.
- dispersionskoefficient: en “catch-all” – betegnelse for en række formler, herunder afstand mellem kvartiler.
- standardafvigelse: sandsynligvis den mest almindelige foranstaltning. Det fortæller dig, hvordan spredte tal er fra middelværdien,
- Dispersionsindeks: et mål for dispersion, der almindeligvis anvendes med nominelle variabler.
- Interquaruartile range (i .r): beskriver, hvor hovedparten af dataene ligger (de “midterste halvtreds” procent).,
- Interdecile range: forskellen mellem den første decil (10%) og den sidste decil (90%).
- rækkevidde: forskellen mellem det mindste og største antal i et sæt data.
- Middelforskel eller forskel i midler: måler den absolutte forskel mellem middelværdien i to forskellige grupper i kliniske forsøg.
- median absolut afvigelse (MAD): medianen af de absolutte afvigelser fra et datasæt median.
- kvartiler: tal, der opdeler dataene i fire kvartaler (første, anden, tredje og fjerde kvartiler).,
i nogle processer, som fremstilling eller måling, er lav dispersion forbundet med høj præcision. Høj dispersion er forbundet med lav præcision.
Dispersionsmål: eksempel
lad os sige, at du blev bedt om at sammenligne dispersionsmålinger for to datasæt. Datasæt A har elementerne 97,98,99,100,101,102,103 og datasæt B har elementer 70,80,90,100,110,120,130. Ved at se på datasættene kan du sandsynligvis fortælle, at midlerne og medianerne er de samme (100), som teknisk kaldes “mål for central tendens” i statistikker.,
imidlertid er området (som giver dig en ID.om, hvor spredt hele datasættet er) meget større for datasæt B (60) sammenlignet med datasæt a (6). Faktisk ville næsten alle spredningsmålinger være ti gange større for datasæt B, hvilket giver mening, da området er ti gange større. Se for eksempel på standardafvigelserne for de to datasæt:
standardafvigelse for a: 2.160246899469287.
standardafvigelse for b: 21.602468994692867.
tallet for datasæt B er nøjagtigt ti gange så stort som A.,advarsel: når du bruger en lommeregner (eller en formel), skal du kontrollere, at du bruger den korrekte indstilling (eller formel) til dine data. Mange dispersionsmålinger (som variansen) har to forskellige formler, en for en population og en for en prøve. Hvis du ikke er sikker på, om du har en prøve eller en befolkning, skal du læse disse artikler:
Hvad er en befolkning i statistik?
prøve i statistik: hvad det er, hvordan man finder det.
Tjek vores statistikker YouTube-kanal., Hundredvis af grundlæggende videoer til en række elementære statistiske emner.
——————————————————————————
brug for hjælp til et hjemmearbejde eller testspørgsmål? Med Chegg Study kan du få trinvise løsninger på dine spørgsmål fra en ekspert på området. Din første 30 minutter med en Chegg tutor er gratis!