Cox Proportional-Hazards Regression Analysis
Survival-Analyse-Methoden kann auch erweitert werden, um zu beurteilen, mehrere Risikofaktoren gleichzeitig ähnlich wie bei der multiplen linearen und der multiplen logistischen Regressionsanalyse, wie beschrieben, in den Modulen diskutieren Confounding, Effect Modification, Korrelation und Multivariate Methoden. Eine der beliebtesten Regressionstechniken für die Überlebensanalyse ist die Cox Proportional Hazards Regression, die verwendet wird, um mehrere Risikofaktoren oder Expositionen, die gleichzeitig betrachtet werden, mit der Überlebenszeit in Beziehung zu setzen., In einem Cox proportional Hazards Regressionsmodell ist das Maß der Wirkung die Gefahrenrate, die das Risiko des Scheiterns ist (dh das Risiko oder die Wahrscheinlichkeit, das Ereignis von Interesse zu erleiden), da der Teilnehmer bis zu einem bestimmten Zeitpunkt überlebt hat. Eine Wahrscheinlichkeit muss im Bereich von 0 bis 1 liegen. Die Gefahr stellt jedoch die erwartete Anzahl von Ereignissen pro Zeiteinheit dar. Infolgedessen kann die Gefahr in einer Gruppe 1 überschreiten. Wenn beispielsweise die Gefahr zum Zeitpunkt t 0, 2 beträgt und die Zeiteinheiten Monate sind, werden durchschnittlich 0, 2 Ereignisse pro Risikoperson und Monat erwartet., Eine andere Interpretation basiert auf der Reziprozität der Gefahr. Zum Beispiel 1/0, 2 = 5, was die erwartete ereignisfreie Zeit (5 Monate) pro Risikoperson ist.
In den meisten Situationen sind wir daran interessiert, Gruppen in Bezug auf ihre Gefahren zu vergleichen, und wir verwenden ein Gefahrenverhältnis, das analog zu einem Odds Ratio bei der Einstellung der multiplen logistischen Regressionsanalyse ist. Das Gefahrenverhältnis kann anhand der Daten geschätzt werden, die wir für die Durchführung des Log-Rank-Tests organisieren., Insbesondere ist das Gefahrenverhältnis das Verhältnis der Gesamtzahl der beobachteten zu erwarteten Ereignissen in zwei unabhängigen Vergleichsgruppen:

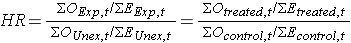
In einigen Studien ist die Unterscheidung zwischen den exponierten oder behandelten Ereignissen im Vergleich zu den nicht exponierten oder Kontrollgruppen klar. In anderen Studien, ist es nicht., Im letzteren Fall kann jede Gruppe im Zähler erscheinen und die Interpretation des Gefahrenverhältnisses ist dann das Ereignisrisiko in der Gruppe im Zähler im Vergleich zum Ereignisrisiko in der Gruppe im Nenner.
In Beispiel 3 werden zwei aktive Behandlungen verglichen (Chemotherapie vor der Operation versus Chemotherapie nach der Operation). Folglich spielt es keine Rolle, welche im Zähler des Gefahrenverhältnisses erscheint., Anhand der Daten in Beispiel 3 wird die Gefährdungsquote wie folgt geschätzt:
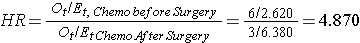
Somit ist das Sterberisiko in der Gruppe Chemotherapie vor Operation im Vergleich zur Gruppe Chemotherapie nach Operation 4.870 mal höher.
Beispiel 3 untersuchte die Assoziation einer einzelnen unabhängigen Variablen (Chemotherapie vor oder nach der Operation) am Überleben. Es ist jedoch häufig von Interesse, den Zusammenhang zwischen mehreren gleichzeitig berücksichtigten Risikofaktoren und der Überlebenszeit zu beurteilen., Eine der beliebtesten Regressionstechniken für Überlebensergebnisse ist die Cox Proportional Hazards Regressionsanalyse. Es gibt mehrere wichtige Annahmen für die geeignete Verwendung des Cox proportional-hazards regression model, einschließlich
- Unabhängigkeit von überlebenszeiten zwischen verschiedenen Personen in der Stichprobe,
- eine multiplikative Beziehung zwischen den Prädiktoren und der Gefahr (im Gegensatz zu einer linearen eins-wie bei der multiplen linearen regression analysis, Ausführlicher besprochen), und
- konstanter hazard-ratio im Laufe der Zeit.,
Das Cox proportional hazards Regressionsmodell kann wie folgt geschrieben werden:
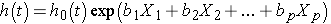
wobei h(t) die erwartete Gefahr zum Zeitpunkt t ist, h0(t) die Ausgangsgefahr ist und die Gefahr darstellt, wenn alle Prädiktoren (oder unabhängige Variablen) X1 , X2, Xp sind gleich Null. Beachten Sie, dass die vorhergesagte Gefahr (dh h(t)) oder die Rate des Leidens des Ereignisses von Interesse im nächsten Moment das Produkt der Grundgefahr (h0(t)) und der Exponentialfunktion der linearen Kombination der Prädiktoren ist., Somit haben die Prädiktoren einen multiplikativen oder proportionalen Effekt auf die vorhergesagte Gefahr.
Betrachten Sie ein einfaches Modell mit einem Prädiktor, X1., Das Cox proportional hazards Modell ist:
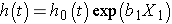
Manchmal wird das Modell anders ausgedrückt und bezieht sich auf die relative Gefahr, die das Verhältnis der Gefahr zum Zeitpunkt t zur Ausgangsgefahr ist, zu den Risikofaktoren:
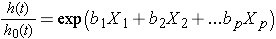
Wir können den natürlichen Logarithmus (ln) jeder Seite des Cox proportional hazards Regressionsmodells verwenden, um Folgendes zu erzeugen, das das Protokoll der relativen Gefahr auf eine lineare Funktion der Prädiktoren bezieht., Beachten Sie, dass die rechte Seite der Gleichung wie die bekanntere lineare Kombination der Prädiktoren oder Risikofaktoren aussieht (wie im multiplen linearen Regressionsmodell zu sehen).
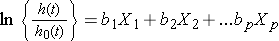
In der Praxis liegt das Interesse an den Assoziationen zwischen den einzelnen Risikofaktoren oder Prädiktoren (X1, X2,…, Xp) und das Ergebnis. Die Assoziationen werden durch die Regressionskoeffizienten Koeffizienten quantifiziert (b1, b2,…, bp)., Die Technik zur Schätzung der Regressionskoeffizienten in einem Cox Proportional hazards Regressionsmodell geht über den Rahmen dieses Textes hinaus und wird in Cox und Oces beschrieben.9 Hier konzentrieren wir uns auf Interpretation. Die geschätzten Koeffizienten im Cox proportional Hazards Regressionsmodell b1 stellen beispielsweise die Änderung des erwarteten Protokolls des Hazards Ratio relativ zu einer Einheitsänderung in X1 dar und halten alle anderen Prädiktoren konstant.
Das Antilog eines geschätzten Regressionskoeffizienten, exp (bi), erzeugt ein Gefahrenverhältnis. Wenn ein Prädiktor dichotom ist (z., ist X1 ein Indikator für prävalente kardiovaskuläre Erkrankungen oder männliches Geschlecht), dann ist exp (b1) das Risikoverhältnis, das das Risiko eines Ereignisses für Teilnehmer mit X1=1 (z. B. prävalente kardiovaskuläre Erkrankungen oder männliches Geschlecht) mit Teilnehmern mit X1=0 (z. B. frei von Herz-Kreislauf-Erkrankungen oder weiblichem Geschlecht) vergleicht.
Wenn das Gefahrenverhältnis für einen Prädiktor nahe bei 1 liegt, beeinflusst dieser Prädiktor das Überleben nicht. Wenn das Gefahrenverhältnis kleiner als 1 ist, dann ist der Prädiktor schützend (d.h.,, verbunden mit verbessertem Überleben) und wenn das Gefahrenverhältnis größer als 1 ist, dann ist der Prädiktor mit erhöhtem Risiko (oder verringertem Überleben) verbunden.
Hypothesentests werden verwendet, um zu beurteilen, ob statistisch signifikante Assoziationen zwischen Prädiktoren und Zeit zu Ereignis bestehen. Die folgenden Beispiele veranschaulichen diese Tests und ihre Interpretation.
Das Cox proportional hazards Modell wird als semiparametrisches Modell bezeichnet, da es keine Annahmen über die Form der Baseline Hazards Funktion gibt. Es gibt jedoch andere Annahmen, wie oben erwähnt (dh,, Unabhängigkeit, Änderungen der Prädiktoren führen unabhängig von der Zeit zu proportionalen Änderungen der Gefahr und zu einer linearen Assoziation zwischen dem natürlichen Logarithmus der relativen Gefahr und den Prädiktoren. Es gibt andere Regressionsmodelle, die in der Überlebensanalyse verwendet werden und spezifische Verteilungen für die Überlebenszeiten annehmen, wie die exponentiellen, Weibull -, Gompertz-und Log-Normalverteilungen1, 8. Das exponentielle Regressionsüberlebensmodell geht beispielsweise davon aus, dass die Gefahrenfunktion konstant ist., Andere Verteilungen gehen davon aus, dass die Gefahr im Laufe der Zeit zunimmt, mit der Zeit abnimmt oder anfänglich zunimmt und dann abnimmt. Beispiel 5 veranschaulicht die Schätzung eines Cox Proportional Hazards Regressionsmodells und diskutiert die Interpretation der Regressionskoeffizienten.
Beispiel:
Eine Analyse wird durchgeführt, um Unterschiede in der Gesamtmortalität zwischen Männern und Frauen zu untersuchen, die an der Framingham Heart Study teilnehmen und sich an das Alter anpassen. Insgesamt 5.180 Teilnehmer im Alter von 45 Jahren und älter werden bis zum Zeitpunkt des Todes oder bis zu 10 Jahren verfolgt, je nachdem, was zuerst eintritt., Sechsundvierzig Prozent der Stichprobe sind männlich, das Durchschnittsalter der Stichprobe beträgt 56, 8 Jahre (Standardabweichung = 8, 0 Jahre) und das Alter liegt zu Beginn der Studie zwischen 45 und 82 Jahren. Unter 5.180 Teilnehmern wurden insgesamt 402 Todesfälle beobachtet. Im Folgenden werden deskriptive Statistiken zum Alter und Geschlecht der Teilnehmer zu Beginn der Studie angezeigt, die danach klassifiziert werden, ob sie während des Follow-up-Zeitraums sterben oder nicht.,
|
|
Die (n=402) |
Do Not Die (n=4778) |
|---|---|---|
|
Mean (SD) Age, years |
65.6 (8.7) |
56.1 (7.,5) |
|
N (%) Männlich |
N (55%) |
2145 (45%) |
Wir schätzen nun ein Cox proportional hazards Regressionsmodell und beziehen einen Indikator für männliches Geschlecht und Alter in Jahren auf die Zeit bis zum Tod. Die Parameterschätzungen werden in SAS unter Verwendung des SAS Cox proportional hazards regression procedure12 generiert und sind unten zusammen mit ihren p-Werten dargestellt.,
|
Risk Factor |
Parameter Estimate |
P-Value |
|---|---|---|
|
Age, years |
0.11149 |
0.0001 |
|
Male Sex |
0.,67958 |
0.0001 |
Beachten Sie, dass ein positiver Zusammenhang zwischen Alter und Gesamtmortalität sowie zwischen männlichem Geschlecht und Gesamtmortalität besteht (dh bei älteren Teilnehmern und Männern besteht ein erhöhtes Sterberisiko).
Wiederum stellen die Parameterschätzungen den Anstieg des erwarteten Protokolls der relativen Gefahr für jede Erhöhung des Prädiktors durch eine Einheit dar, wobei andere Prädiktoren konstant gehalten werden. Es gibt eine 0.,11149 Anstieg des erwarteten Logs der relativen Gefahr für jedes Jahr Anstieg des Alters, Halten des Geschlechts konstant, und ein Anstieg des erwarteten Logs der relativen Gefahr für Männer um 0,67958 Einheiten im Vergleich zu Frauen, Halten des Alters konstant.
Zur Interpretation berechnen wir Gefahrenverhältnisse durch Exponentiation der Parameterschätzungen. Für Alter, exp(0.11149) = 1.118. Es gibt einen Anstieg der erwarteten Gefahr um 11, 8% im Vergleich zu einem Anstieg des Alters um ein Jahr (oder die erwartete Gefahr ist 1, 12-mal höher bei einer Person, die ein Jahr älter ist als eine andere), wobei der Sex konstant bleibt. Ähnlich ist exp (0.67958) = 1.,973. Die erwartete Gefahr ist bei Männern 1.973 mal höher als bei Frauen und hält das Alter konstant.
Angenommen, wir berücksichtigen zusätzliche Risikofaktoren für die Gesamtmortalität und schätzen ein Cox proportional hazards Regressionsmodell, das einen erweiterten Satz von Risikofaktoren auf die Zeit bis zum Tod bezieht. Die Parameterschätzungen werden wiederum in SAS unter Verwendung des SAS Cox proportional hazards regression Procedure generiert und sind unten zusammen mit ihren p-Werten dargestellt.12 Weiter unten sind die Gefahrenverhältnisse zusammen mit ihren 95% – Konfidenzintervallen aufgeführt.,
Alle Parameterschätzungen werden unter Berücksichtigung der anderen Prädiktoren geschätzt. Nach Berücksichtigung von Alter, Geschlecht, Blutdruck und Raucherstatus gibt es keine statistisch signifikanten Assoziationen zwischen Gesamtcholesterin im Serum und Gesamtmortalität oder zwischen Diabetes und Gesamtmortalität. Dies bedeutet nicht, dass diese Risikofaktoren nicht mit der Gesamtmortalität verbunden sind; Ihre mangelnde Bedeutung ist wahrscheinlich auf Verwirrung zurückzuführen (Zusammenhänge zwischen den betrachteten Risikofaktoren). Für die statistisch signifikanten Risikofaktoren (z.,, Alter, Geschlecht, systolischer Blutdruck und aktueller Raucherstatus), dass die 95% – Konfidenzintervalle für die Gefahrenverhältnisse nicht 1 enthalten (der Nullwert). Im Gegensatz dazu umfassen die 95%-Konfidenzintervalle für die nicht signifikanten Risikofaktoren (Gesamtcholesterin im Serum und Diabetes) den Nullwert.
Beispiel:
Eine prospektive Kohortenstudie wird durchgeführt, um den Zusammenhang zwischen dem Body-Mass-Index und der Zeit bis zum Auftreten von Herz-Kreislauf-Erkrankungen (CVD) zu bewerten. Zu Studienbeginn wird der Body-Mass-Index der Teilnehmer zusammen mit anderen bekannten klinischen Risikofaktoren für Herz-Kreislauf-Erkrankungen (z.,, alter, Geschlecht, Blutdruck). Die Teilnehmer werden für bis zu 10 Jahre für die Entwicklung von CVD verfolgt. In der Studie mit n=3.937 Teilnehmern entwickeln 543 während des Beobachtungszeitraums der Studie eine CVD. In einer Cox Proportional Hazards Regressionsanalyse finden wir den Zusammenhang zwischen BMI und Zeit zu CVD statistisch signifikant mit einer Parameterschätzung von 0,02312 (p=0,0175) relativ zu einer Einheitsänderung des BMI.
Wenn wir die Parameterschätzung exponentiieren, haben wir ein Gefahrenverhältnis von 1.023 mit einem Konfidenzintervall von (1.004-1.043)., Da wir den BMI als kontinuierlichen Prädiktor modellieren, ist die Interpretation des Gefahrenverhältnisses für CVD relativ zu einer Änderung des BMI um eine Einheit (der BMI wird als Verhältnis von Gewicht in Kilogramm zu Körpergröße im Quadrat gemessen). Ein Anstieg des BMI um eine Einheit ist mit einem Anstieg der erwarteten Gefahr um 2, 3% verbunden.
Um die Interpretation zu erleichtern, nehmen wir an, wir erstellen 3 Gewichtskategorien, die durch den BMI des Teilnehmers definiert sind.
- Normalgewicht ist definiert als BMI < 25.0,
- Übergewicht als BMI zwischen 25.0 und 29.9 und
- Fettleibig als BMI über 29.9.,
In der Probe, gibt es 1,651 (42%) Teilnehmer, die unter die definition des normalen Gewicht, auch 1.648 (42%), die der definition von übergewicht und 638 (16%), die der definition von fettleibig. Die Anzahl der CVD-Ereignisse in jeder der 3 Gruppen ist unten dargestellt.,
|
Group |
Number of Participants |
Number (%) of CVD Events |
|---|---|---|
|
Normal Weight |
1651 |
202 (12.,2%) |
|
Overweight |
1648 |
241 (14.6%) |
|
Obese |
638 |
100 (15.7%) |
The incidence of CVD is higher in participants classified as overweight and obese as compared to participants of normal weight.,
Wir verwenden jetzt die Cox proportional hazards Regression Analysis, um die Daten aller Studienteilnehmer maximal zu nutzen. Die folgende Tabelle zeigt die Parameterschätzungen, p-Werte, Gefahrenverhältnisse und 95% Konfidenzintervalle für die Gefahrenverhältnisse, wenn wir die Gewichtsgruppen allein betrachten (nicht angepasstes Modell), wenn wir uns an Alter und Geschlecht anpassen und wenn wir uns an Alter, Geschlecht und andere bekannte klinische Risikofaktoren für CVD anpassen.
Die beiden letzteren Modelle sind multivariable Modelle und werden durchgeführt, um den Zusammenhang zwischen Gewicht und Vorfall CVD Anpassung für confounders zu bewerten., Da wir drei Gewichtsgruppen haben, benötigen wir zwei Dummy-Variablen oder Indikatorvariablen, um die drei Gruppen darzustellen. In den Modellen enthalten wir die Indikatoren für Übergewicht und Fettleibigkeit und betrachten normales Gewicht als Referenzgruppe.
* Angepasst für alter, geschlecht, systolischen blutdruck, behandlung für bluthochdruck, aktuelle rauchen status, insgesamt serum cholesterin.
Im nicht angepassten Modell besteht ein erhöhtes CVD-Risiko bei übergewichtigen Teilnehmern im Vergleich zum Normalgewicht und bei Adipösen im Vergleich zu normalgewichtigen Teilnehmern (Gefahrenverhältnisse von 1.215 und 1.,310, respectively). Nach Anpassung an Alter und Geschlecht gibt es jedoch keinen statistisch signifikanten Unterschied zwischen übergewichtigen und normalgewichtigen Teilnehmern hinsichtlich des CVD-Risikos (Hazard ratio = 1.067, p=0, 5038). Gleiches gilt für das Modell, das sich an Alter, Geschlecht und die klinischen Risikofaktoren anpasst. Nach der Anpassung bleibt der Unterschied im CVD-Risiko zwischen übergewichtigen und normalgewichtigen Teilnehmern jedoch statistisch signifikant, wobei das CVD-Risiko bei übergewichtigen Teilnehmern im Vergleich zu Teilnehmern mit normalem Gewicht um etwa 30% steigt.,
zurück nach oben | vorherige Seite / nächste Seite