El análisis de regresión de riesgos proporcionales de Cox
Los métodos de análisis de supervivencia también se pueden ampliar para evaluar varios factores de riesgo simultáneamente similares al análisis de regresión logística múltiple y lineal múltiple como se describe en los módulos que discuten la confusión, la modificación del efecto, la correlación y los métodos multivariables. Una de las técnicas de regresión más populares para el análisis de supervivencia es la regresión de riesgos proporcionales de Cox, que se utiliza para relacionar varios factores de riesgo o exposiciones, consideradas simultáneamente, con el tiempo de supervivencia., En un modelo de regresión de riesgos proporcionales de Cox, la medida del efecto es la tasa de riesgo, que es el riesgo de fracaso (es decir, el riesgo o probabilidad de sufrir el evento de interés), dado que el participante ha sobrevivido hasta un tiempo específico. Una probabilidad debe estar en el rango de 0 a 1. Sin embargo, el peligro representa el número esperado de eventos por unidad de tiempo. Como resultado, el peligro en un grupo puede exceder 1. Por ejemplo, si el peligro es 0,2 en el tiempo t y las unidades de tiempo son meses, entonces en promedio, se esperan 0,2 eventos por persona en riesgo por mes., Otra interpretación se basa en el recíproco del peligro. Por ejemplo, 1/0.2 = 5, que es el tiempo libre esperado (5 meses) por persona en riesgo.
en la mayoría de las situaciones, estamos interesados en Comparar grupos con respecto a sus peligros, y utilizamos un hazard ratio, que es análogo a un odds ratio en el marco del análisis de regresión logística múltiple. El hazard ratio se puede estimar a partir de los datos que organizamos para llevar a cabo la prueba de rango logarítmico., Específicamente, el hazard ratio es la relación entre el número total de eventos observados y esperados en dos grupos de comparación independientes:

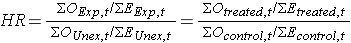
en algunos estudios, la distinción entre los grupos expuestos o tratados en comparación con los no expuestos o de control es clara. En otros estudios, no lo es., En este último caso, cualquiera de los grupos puede aparecer en el numerador y la interpretación de la razón de riesgo es entonces el riesgo de evento en el grupo en el numerador en comparación con el riesgo de evento en el grupo en el denominador.
en el Ejemplo 3 se comparan dos tratamientos activos (quimioterapia antes de la cirugía versus quimioterapia después de la cirugía). En consecuencia, no importa lo que aparezca en el numerador del hazard ratio., Utilizando los datos del Ejemplo 3, el hazard ratio se estima como:
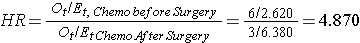
por lo tanto, el riesgo de muerte es 4,870 veces mayor en el grupo de quimioterapia antes de la cirugía en comparación con el grupo de quimioterapia después de la cirugía.
en el Ejemplo 3 se examinó la relación de una sola variable independiente (quimioterapia antes o después de la cirugía) con la supervivencia. Sin embargo, a menudo es de interés evaluar la asociación entre varios factores de riesgo, considerados simultáneamente, y el tiempo de supervivencia., Una de las técnicas de regresión más populares para los resultados de supervivencia es el análisis de regresión de riesgos proporcionales de Cox. Hay varios supuestos importantes para el uso apropiado del modelo de regresión de riesgos proporcionales de Cox, incluyendo
- independencia de los tiempos de supervivencia entre individuos distintos en la muestra,
- Una relación multiplicativa entre los predictores y el riesgo (en oposición a una lineal como fue el caso con el análisis de regresión lineal múltiple, discutido en más detalle a continuación), y
- Una razón de riesgos constante a lo largo del tiempo.,
el modelo de regresión de riesgos proporcionales de Cox se puede escribir de la siguiente manera:
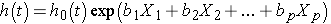
donde h(t) es el peligro esperado en el tiempo t, h0(t) es el peligro basal y representa el riesgo cuando todos los predictores (o variables independientes) X1, X2 , XP son iguales a cero. Observe que el peligro predicho (es decir, h (t)), o la tasa de sufrir el evento de interés en el siguiente instante, es el producto del peligro de referencia (h0(t)) y la función exponencial de la combinación lineal de los predictores., Por lo tanto, los predictores tienen un efecto multiplicativo o proporcional sobre el peligro predicho.
considere un modelo simple con un predictor, X1., El modelo de riesgos proporcionales de Cox es:
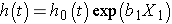
a veces el modelo se expresa de manera diferente, relacionando el peligro relativo, que es la relación del peligro en el tiempo t con el peligro basal, con los factores de riesgo:
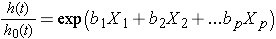
podemos tomar el logaritmo natural (ln) de cada lado del modelo de regresión de riesgos proporcionales de Cox, para producir lo siguiente que relaciona el registro del riesgo relativo con una función lineal de los predictores., Observe que el lado derecho de la ecuación se parece a la combinación lineal más familiar de los predictores o factores de riesgo (como se ve en el modelo de regresión lineal múltiple).
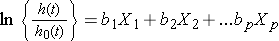
En la práctica, el interés radica en las asociaciones entre cada uno de los factores de riesgo o predictores (X1, X2, …, Xp) y el resultado. Las asociaciones se cuantifican por los coeficientes de regresión coeficientes (B1, b2, …, bp)., La técnica para estimar los coeficientes de regresión en un modelo de regresión de riesgos proporcionales de Cox está fuera del alcance de este texto y se describe en Cox y Oakes.9 Aquí nos centramos en la interpretación. Los coeficientes estimados en el modelo de regresión de riesgos proporcionales de Cox, b1, por ejemplo, representan el cambio en el logaritmo esperado de la razón de riesgos en relación con un cambio de una unidad en X1, manteniendo constantes todos los demás predictores.
el antilog de un coeficiente de regresión estimado, exp (bi), produce un hazard ratio. Si un predictor es dicotómico (p. ej.,, X1 es un indicador de enfermedad cardiovascular prevalente o sexo masculino) entonces exp (B1) es la razón de riesgo que compara el riesgo de evento para los participantes con X1=1 (por ejemplo, enfermedad cardiovascular prevalente o sexo masculino) a los participantes con X1=0 (por ejemplo, libre de enfermedad cardiovascular o sexo femenino).
si el hazard ratio para un predictor es cercano a 1, ese predictor no afecta la supervivencia. Si el hazard ratio es menor que 1, entonces el predictor es protector (p. ej.,, asociado con una mejor supervivencia) y si el hazard ratio es mayor que 1, entonces el predictor se asocia con un aumento del riesgo (o disminución de la supervivencia).
Las pruebas de hipótesis se utilizan para evaluar si hay asociaciones estadísticamente significativas entre los predictores y el tiempo hasta el evento. Los ejemplos que siguen ilustran estas pruebas y su interpretación.
el modelo de riesgos proporcionales de Cox se denomina modelo semi-paramétrico, porque no hay suposiciones sobre la forma de la función de riesgo basal. Sin embargo, hay otros supuestos como se señaló anteriormente (i. e.,, independencia, cambios en los predictores producen cambios proporcionales en el peligro independientemente del tiempo, y una asociación lineal entre el logaritmo natural del peligro relativo y los predictores). Existen otros modelos de regresión utilizados en el análisis de supervivencia que asumen distribuciones específicas para los tiempos de supervivencia como las distribuciones exponencial, Weibull, Gompertz y log-normal1,8. El modelo de supervivencia de regresión exponencial, por ejemplo, asume que la función de riesgo es constante., Otras distribuciones asumen que el peligro está aumentando con el tiempo, disminuyendo con el tiempo, o aumentando inicialmente y luego disminuyendo. El ejemplo 5 ilustrará la estimación de un modelo de regresión de riesgos proporcionales de Cox y discutirá la interpretación de los coeficientes de regresión.
ejemplo:
se realiza un análisis para investigar las diferencias en la mortalidad por todas las causas entre hombres y mujeres que participaron en el Framingham Heart Study ajustando por edad. Un total de 5.180 participantes de 45 años o más son seguidos hasta el momento de la muerte o hasta los 10 años, lo que ocurra primero., Cuarenta y seis por ciento de la muestra son hombres, la edad media de la muestra es de 56,8 años ( desviación estándar = 8,0 años) y las edades oscilan entre 45 y 82 años al inicio del estudio. Hay un total de 402 muertes observadas entre 5.180 participantes. A continuación se presentan estadísticas descriptivas sobre la edad y el sexo de los participantes al inicio del estudio, clasificados según si fallecen o no durante el período de seguimiento.,
|
|
Die (n=402) |
Do Not Die (n=4778) |
|---|---|---|
|
Mean (SD) Age, years |
65.6 (8.7) |
56.1 (7.,5) |
|
N (%) Masculino |
221 (55%) |
2145 (45%) |
ahora estimación de riesgos proporcionales de Cox modelo de regresión y se relacionan de un indicador de sexo masculino y la edad, en años, para el momento de la muerte. Las estimaciones de parámetros se generan en SAS utilizando el procedimiento de regresión de riesgos proporcionales de COX de SAS12 y se muestran a continuación junto con sus valores P.,
|
Risk Factor |
Parameter Estimate |
P-Value |
|---|---|---|
|
Age, years |
0.11149 |
0.0001 |
|
Male Sex |
0.,67958 |
0.0001 |
tenga en cuenta que hay una asociación positiva entre la edad y la mortalidad por todas las causas y entre el sexo masculino y la mortalidad por todas las causas (es decir, hay un mayor riesgo de muerte para los participantes mayores y para los hombres).
nuevamente, las estimaciones de los parámetros representan el aumento en el log esperado del riesgo relativo para cada unidad de aumento en el predictor, manteniendo constantes los otros predictores. Hay un 0.,11149 aumento unitario en el logaritmo esperado del peligro relativo por cada año aumento de la edad, manteniendo constante el sexo, y un aumento unitario de 0,67958 en el logaritmo esperado del peligro relativo para los hombres en comparación con las mujeres, manteniendo constante la edad.
para la interpretabilidad, calculamos las razones de riesgo exponenciando las estimaciones de los parámetros. Para la edad, CAD ( 0,11149) = 1,118. Hay un aumento del 11,8% en el riesgo esperado en relación con un aumento de un año en la edad (o el riesgo esperado es 1,12 veces mayor en una persona que es un año mayor que otra), manteniendo el sexo constante. Del mismo modo, exp(0,67958) = 1.,973. El riesgo esperado es 1,973 veces mayor en hombres que en mujeres, manteniendo la edad constante.
supongamos que consideramos factores de riesgo adicionales para la mortalidad por todas las causas y estimamos un modelo de regresión de riesgos proporcionales de Cox que relaciona un conjunto ampliado de factores de riesgo con el tiempo hasta la muerte. Las estimaciones de los parámetros se generan nuevamente en SAS utilizando el procedimiento de regresión de riesgos proporcionales de Cox DE SAS y se muestran a continuación junto con sus valores de P.12 también se incluyen a continuación las razones de riesgo junto con sus intervalos de confianza del 95%.,
todas las estimaciones de parámetros se estiman teniendo en cuenta los otros predictores. Después de tener en cuenta la edad, el sexo, la presión arterial y el tabaquismo, no hay asociaciones estadísticamente significativas entre el colesterol sérico total y la mortalidad por todas las causas o entre la diabetes y la mortalidad por todas las causas. Esto no quiere decir que estos factores de riesgo no estén asociados con la mortalidad por todas las causas; su falta de significación se debe probablemente a la confusión (interrelaciones entre los factores de riesgo considerados). Observe que para los factores de riesgo estadísticamente significativos (es decir,,, edad, sexo, presión arterial sistólica y tabaquismo actual), que los intervalos de confianza del 95% para los hazard ratio no incluyen 1 (el valor nulo). Por el contrario, los intervalos de confianza del 95% para los factores de riesgo no significativos (colesterol sérico total y diabetes) incluyen el valor nulo.
ejemplo:
se realiza un estudio de cohorte prospectivo para evaluar la asociación entre el índice de masa corporal y el tiempo hasta la enfermedad cardiovascular incidente (ECV). Al inicio, el índice de masa corporal de los participantes se mide junto con otros factores de riesgo clínicos conocidos de enfermedad cardiovascular (p. ej.,, edad, sexo, presión arterial). Los participantes son seguidos por hasta 10 años para el desarrollo de ECV. En el estudio de n=3.937 Participantes, 543 desarrollaron ECV durante el período de observación del estudio. En un análisis de regresión de riesgos proporcionales de Cox, encontramos la asociación entre el IMC y el tiempo hasta la ECV estadísticamente significativa con una estimación de parámetros de 0.02312 (p=0.0175) en relación con un cambio de una unidad en el IMC.
Si exponenciamos la estimación del parámetro, tenemos un hazard ratio de 1.023 con un intervalo de confianza de (1.004-1.043)., Debido a que modelamos el IMC como un predictor continuo, la interpretación de la razón de riesgo para ECV es relativa a un cambio de una unidad en el IMC (recuerdo IMC se mide como la relación de peso en kilogramos a la altura en metros cuadrados). Un aumento de una unidad en el IMC se asocia con un aumento del 2,3% en el riesgo esperado.
para facilitar la interpretación, supongamos que creamos 3 categorías de peso definidas por el IMC del participante.
- peso Normal se define como un IMC < 25.0,
- Sobrepeso cuando el IMC entre 25.0 y 29.9, y
- Obesidad como IMC superior a 29,9.,
en la muestra, hay 1.651 Participantes (42%) que cumplen con la definición de peso normal, 1.648 (42%) que cumplen con la definición de peso excesivo y 638 (16%) que cumplen con la definición de obesidad. Los números de eventos de ECV en cada uno de los 3 grupos se muestran a continuación.,
|
Group |
Number of Participants |
Number (%) of CVD Events |
|---|---|---|
|
Normal Weight |
1651 |
202 (12.,2%) |
|
Overweight |
1648 |
241 (14.6%) |
|
Obese |
638 |
100 (15.7%) |
The incidence of CVD is higher in participants classified as overweight and obese as compared to participants of normal weight.,
ahora utilizamos el análisis de regresión de riesgos proporcionales de Cox para aprovechar al máximo los datos de todos los participantes en el estudio. La siguiente tabla muestra las estimaciones de los parámetros, los valores de p, Los hazard ratios y los intervalos de confianza del 95% para los Hazard ratios cuando consideramos los grupos de peso solos (modelo no ajustado), cuando ajustamos por edad y sexo y cuando ajustamos por edad, sexo y otros factores de riesgo clínicos conocidos para ECV incidente.
estos dos últimos modelos son modelos multivariables y se realizan para evaluar la asociación entre peso y ECV incidente ajustando por factores de confusión., Debido a que tenemos tres grupos de peso, necesitamos dos variables ficticias o variables indicadoras para representar los tres grupos. En los modelos incluimos los indicadores de sobrepeso y obesidad y consideramos el peso normal como el grupo de referencia.
* ajustado por edad, sexo, presión arterial sistólica, tratamiento de la hipertensión, tabaquismo actual, colesterol sérico total.
en el modelo no AJUSTADO, hay un mayor riesgo de ECV en los participantes con sobrepeso en comparación con el peso normal y en los obesos en comparación con los participantes con peso normal (razón de riesgo de 1,215 y 1.,310, respectivamente). Sin embargo, después del ajuste por edad y sexo, no hay diferencia estadísticamente significativa entre los participantes con sobrepeso y peso normal en términos de riesgo de ECV (hazard ratio = 1,067, p=0,5038). Lo mismo ocurre en el modelo de ajuste por edad, sexo y factores de riesgo clínicos. Sin embargo, después del ajuste, la diferencia en el riesgo de ECV entre los participantes obesos y de peso normal sigue siendo estadísticamente significativa, con aproximadamente un aumento del 30% en el riesgo de ECV entre los participantes obesos en comparación con los participantes de peso normal.,
volver al principio | página anterior / Página siguiente