¿qué es la arquitectura de redes neuronales convolucionales?
este artículo fue publicado como parte de la Data Science Blogathon.
Introducción
trabajando en un proyecto de reconocimiento de imágenes o detección de objetos, pero no tenía los conceptos básicos para construir una arquitectura?,
en este artículo, veremos qué son las arquitecturas de redes neuronales convolucionales desde basic y tomaremos una arquitectura básica como caso de estudio para aplicar nuestros aprendizajes, el único requisito previo es que solo necesita saber cómo funciona la convolución, pero no se preocupe, ¡es muy simple !!
tomemos una red neuronal convolucional simple,
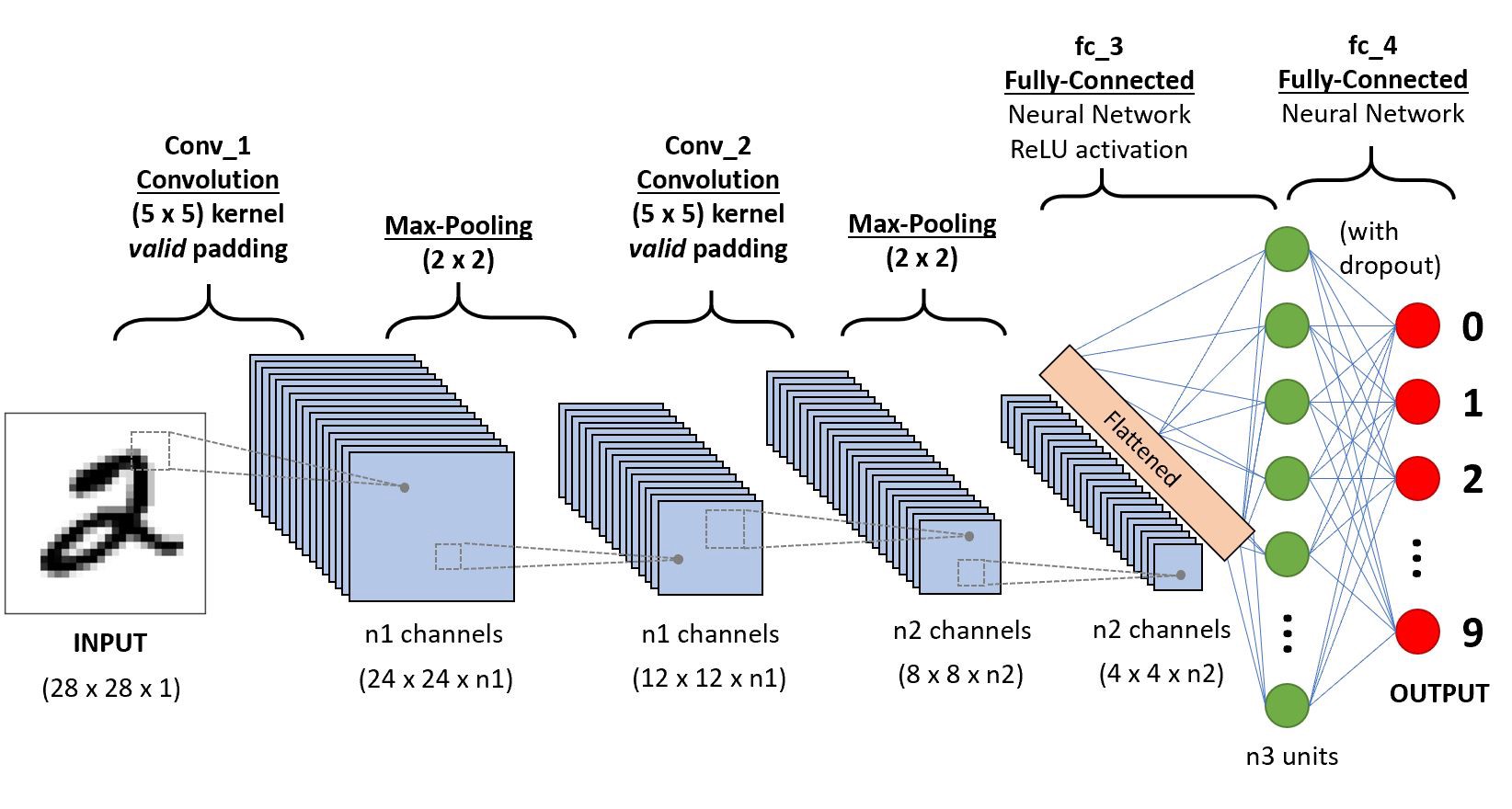
iremos a nivel de capa para obtener información profunda sobre esta CNN.,
en primer lugar, hay algunas cosas que aprender de la capa 1 que es zancadas y relleno, vamos a ver cada uno de ellos en breve con ejemplos
supongamos que esto en la matriz de entrada de 5×5 y un filtro de matriz 3X3, para aquellos que no saben lo que un filtro es un conjunto de pesos en una matriz aplicada en una imagen o una matriz para obtener las características requeridas, por favor busque en convolución si esta es su primera vez!
Nota: Siempre tomamos la suma o el promedio de todos los valores mientras hacemos una convolución.,
Un filtro puede ser de cualquier profundidad, si un filtro está teniendo una profundidad d puede ir a una profundidad de capas d y contortos yo.,»f4a6da248a»>
Aquí la entrada es de tamaño 5×5 Después de aplicar un kernel o filtros de 3×3, obtiene un mapa de características de salida de 3×3, Así que intentemos formular esto
.png)
así que se formula la altura de salida y lo mismo con el ancho de O/P también
padding
mientras aplicamos convoluciones No obtendremos las dimensiones de salida igual que las de entrada perderemos datos sobre los bordes por lo que añadimos un borde de ceros y recalculamos la convolución cubriendo todos los valores de entrada.,r ancho también
Anda
Algunas veces no queremos capturar todos los datos o la información disponible, así que nos saltamos algunas células vecinas nos deja visualizarlo,
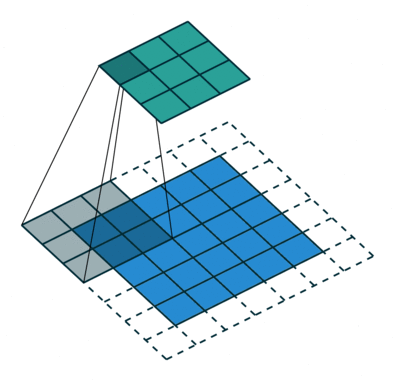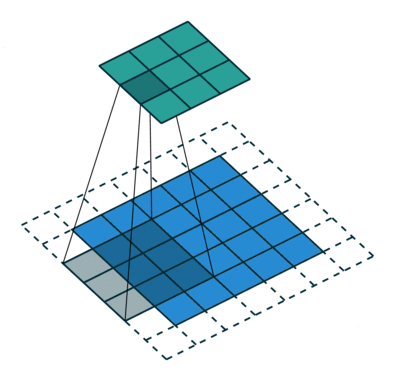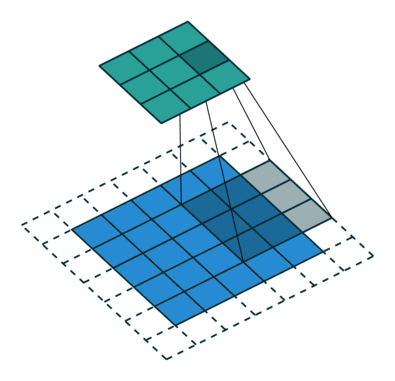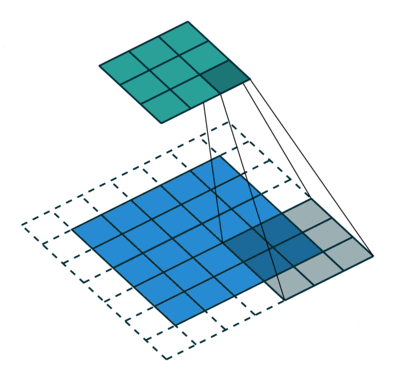
Aquí la matriz de entrada o la imagen es de dimensiones 5 x 5 con un filtro de 3×3 y a un paso de 2 así que cada vez nos saltamos dos columnas y contortos, formulamos esta
.png)
Si las dimensiones son de flotador puede tomar ceil() en la salida de la i.,e (next close integer)
Aquí H se refiere a la altura, por lo que la altura de salida se formula y lo mismo con el ancho de o/p también y aquí 2 es el valor de zancada para que pueda hacerlo como S en las fórmulas.
Pooling
en términos generales, pooling se refiere a una pequeña porción, así que aquí tomamos una pequeña porción de la entrada y tratamos de tomar el valor promedio referido como pooling promedio o tomar un valor máximo denominado como pooling máximo, por lo que al hacer pooling en una imagen no estamos sacando todos los valores que estamos tomando un valor resumido sobre todos los valores presentes !!!,

aquí este es un ejemplo de max agrupación así que aquí tomando un paso de dos estamos tomando el valor máximo presente en la matriz
función de Activación
La función de activación es un nodo que se pone al final o entre las Redes Neuronales. Ayudan a decidir si la neurona se dispararía o no., Tenemos diferentes tipos de funciones de activación al igual que en la figura anterior, pero para este post, mi enfoque será en la unidad lineal rectificada (ReLU)
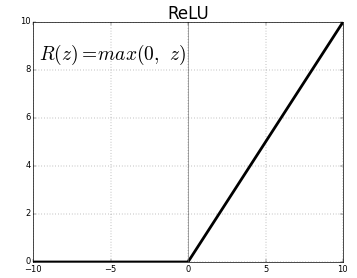
no deje caer sus mandíbulas, esto no es que compleja esta función simplemente devuelve 0 si su valor es negativo de lo contrario devuelve el mismo valor que dio, nada más que elimina salidas negativas y mantiene valores entre 0 a +infinito
ahora, que hemos aprendido todos los conceptos básicos necesarios vamos a estudiar una red neuronal básica llamada lenet.,
LeNet-5
antes de comenzar veremos cuáles son las arquitecturas diseñadas hasta la fecha.,ures
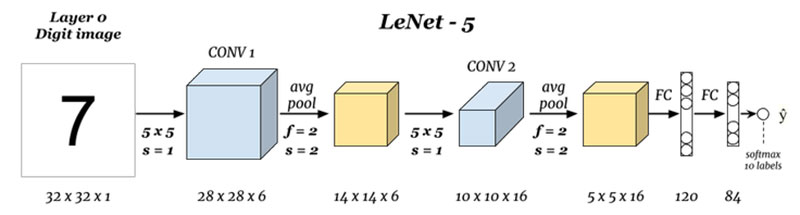
¿cuáles son las entradas y salidas (Capa 0 y la Capa N) :
Aquí estamos prediciendo dígitos basado en la imagen de entrada dado, tenga en cuenta que aquí la imagen es de dimensiones altura = 32 píxeles, width = 32 píxeles y una profundidad de 1, por lo que podemos asumir que se trata de una imagen en escala de grises o blanco y negro, teniendo que en cuenta que la salida es una softmax de todos los 10 valores, aquí softmax da las probabilidades o las proporciones de 10 dígitos, se puede tomar el número como el producto con más alta probabilidad o proporción.,ef5″>
Aquí estamos tomando la entrada y convoluting con filtros de tamaño 5 x 5 produciendo así una salida de tamaño 28 x 28 compruebe la fórmula anterior para calcular las dimensiones de salida, la cosa aquí es que hemos tomado 6 tales filtros y por lo tanto la profundidad de conv1 es 6, por lo tanto sus dimensiones eran, 28 x 28 x 6 ahora pase esto a la capa de pooling
Pooling 1 (capa 2) :
.png)
Aquí estamos tomando el 28 x 28 x 6 como entrada y aplicando el pooling promedio de una matriz de 2×2 y una zancada de 2 I.,e flotando una matriz de 2 x 2 en la entrada y tomando el promedio de todos esos cuatro píxeles y saltando con un salto de 2 columnas cada vez, dando 14 x 14 x 6 como salida, estamos computando la agrupación para cada capa, así que aquí la profundidad de salida es 6
convolución 2 (capa 3) :
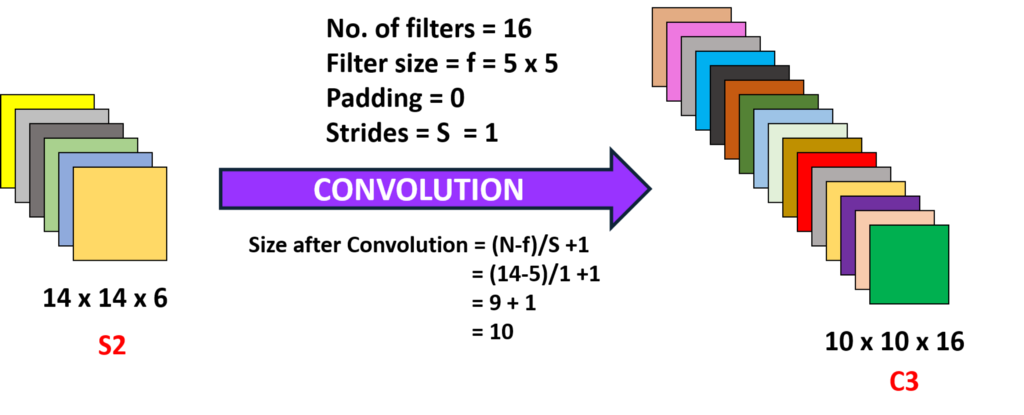
Aquí estamos tomando el 14 x 14 x 6 es decir, el O/P anterior y convoluting con un filtro de tamaño 5 x5, con una zancada de 1 i.,e (sin omitir), y con cero rellenos para obtener una salida de 10 x 10, Ahora aquí estamos tomando 16 tales filtros de profundidad 6 y convoluting obteniendo así una salida de 10 x 10 x 16
Pooling 2 (capa 4):

Aquí estamos tomando la salida de la capa anterior y realizando un pooling promedio con una zancada de 2 i.,yer (N-1) :
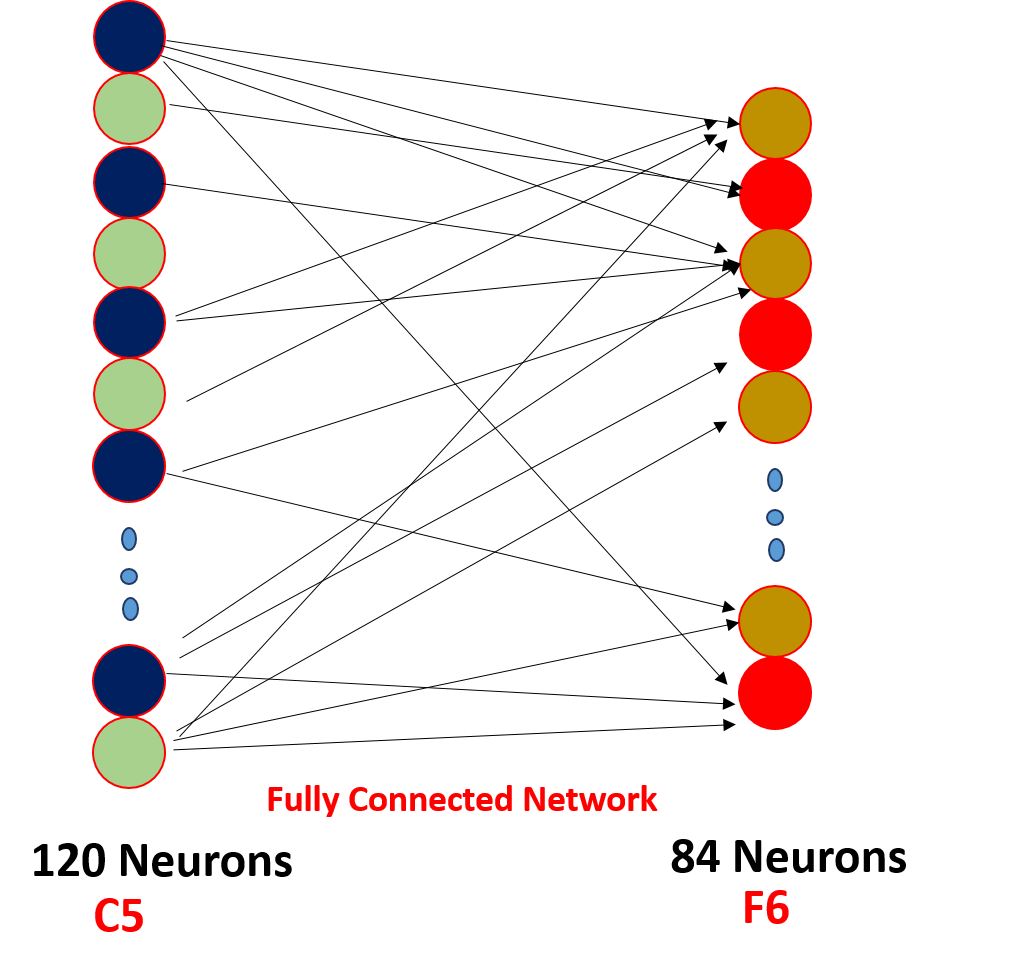
finalmente, aplanamos todos los 5 x 5 x 16 a una sola capa de valores de tamaño 400 y los ingresamos a una red neuronal de alimentación de 120 neuronas que tienen una matriz de peso de tamaño y una capa oculta de 84 neuronas conectadas por las 120 neuronas con una matriz de peso de y estas 84 neuronas de hecho están conectadas a 10 neuronas de salida
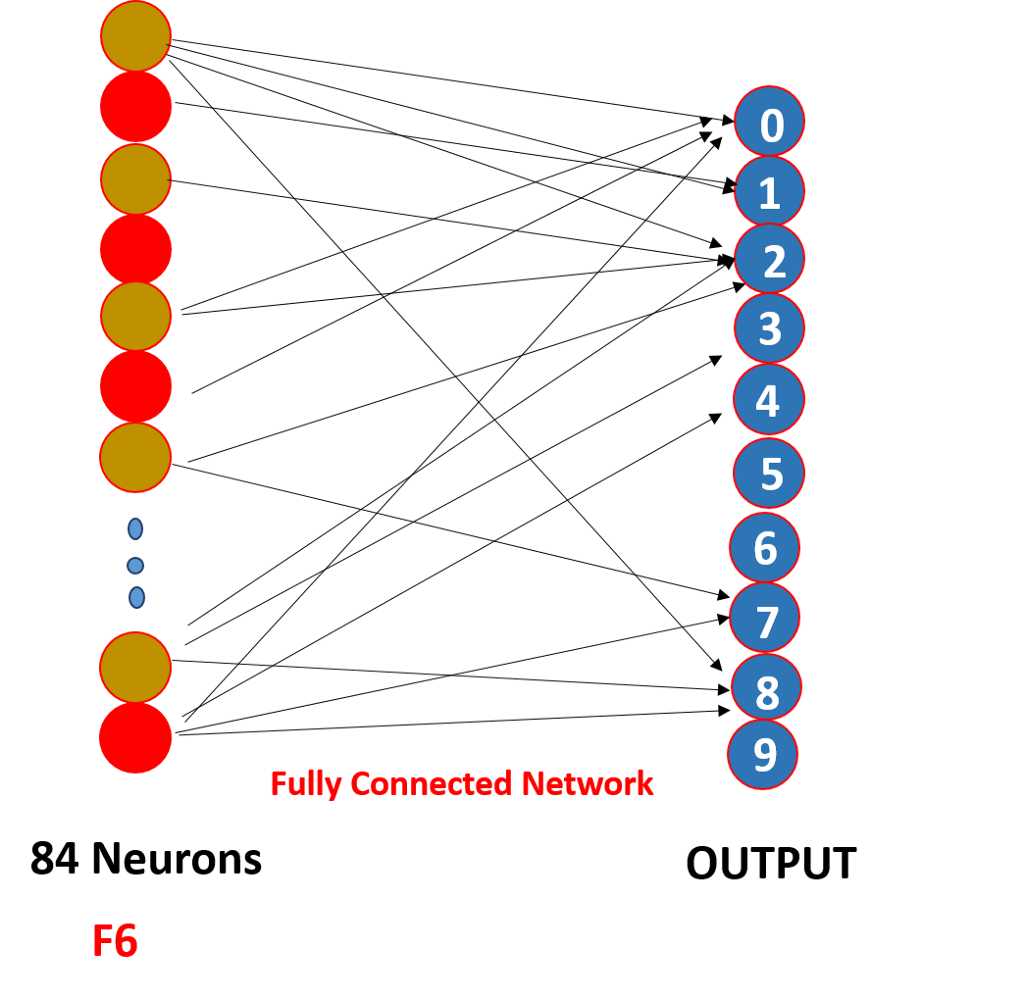
estas neuronas o/p finalizan el número predicho por softmaxing .,
¿cómo funciona realmente una red neuronal convolucional?,
funciona a través de la distribución de peso y la conectividad escasa,
.png)
así que aquí como se puede ver la convolución tiene algunos pesos estos pesos son compartidos por todas las neuronas de entrada, no la entrada tiene un peso separado llamado Peso compartido, y no todas las neuronas de entrada están conectadas a la neurona de salida a’o solo algunas que están enrevesadas se disparan conocida como conectividad dispersa, CNN no es diferente de las redes neuronales de alimentación estas dos propiedades las hacen especiales !!!,
puntos a mirar
1. Después de cada convolución, la salida se envía a una función de activación para obtener mejores características y mantener la positividad, por ejemplo: ReLu
2. La escasa conectividad y el reparto de peso son la razón principal para que una red neuronal convolucional funcione
3. El concepto de elegir una serie de filtros entre capas y relleno y zancada y dimensiones de filtro se toman en hacer una serie de experimentaciones, no se preocupe por eso, centrarse en la construcción de la base, algún día va a hacer esos experimentos y construir uno más productivo!!!,
Usted también puede leer este artículo en nuestra APLICACIÓN Móvil![]()
