Analyse de régression des risques proportionnels de Cox
Les méthodes d’analyse de survie peuvent également être étendues pour évaluer plusieurs facteurs de risque simultanément, similaires à l’analyse de régression linéaire et logistique multiple décrite dans les modules traitant des méthodes de confusion, de Modification des effets, de corrélation et multivariables. L’une des techniques de régression les plus populaires pour l’analyse de la survie est la régression proportionnelle des risques de Cox, qui est utilisée pour relier plusieurs facteurs de risque ou expositions, considérés simultanément, au temps de survie., Dans un modèle de régression des risques proportionnels de Cox, la mesure de l’effet est le taux de danger, qui est le risque d’échec (c.-à-d. le risque ou la probabilité de subir l’événement d’intérêt), étant donné que le participant a survécu jusqu’à un moment précis. Une probabilité doit se situer entre 0 et 1. Cependant, le danger représente le nombre d’événements par unité de temps. En conséquence, le danger dans un groupe peut dépasser 1. Par exemple, si le danger est de 0,2 à l’instant t et que les unités de temps sont des mois, en moyenne, 0,2 événement est attendu par personne à risque par mois., Une autre interprétation est basée sur la réciproque du danger. Par exemple, 1/0, 2 = 5, qui est le temps sans événement prévu (5 mois) par personne à risque.
dans la plupart des situations, nous sommes intéressés à comparer les groupes par rapport à leurs dangers, et nous utilisons un rapport de danger, qui est analogue à un rapport de cotes dans le cadre de l’analyse de régression logistique multiple. Le rapport de risque peut être estimé à partir des données que nous organisons pour effectuer le test de classement log., Plus précisément, le rapport de risque est le rapport du nombre total d’observations d’événements attendus dans les deux groupes de comparaison:

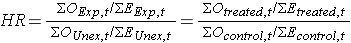
Dans certaines études, la distinction entre les exposés ou traités par rapport aux témoins non exposés ou les groupes de contrôle sont claires. Dans d’autres études, il n’est pas., Dans ce dernier cas, le groupe peut apparaître dans le numérateur et l’interprétation du rapport de risque est le risque d’événements dans le groupe dans le numérateur contre le risque d’événements dans le groupe dans le dénominateur.
dans L’exemple 3, deux traitements actifs sont comparés (chimiothérapie avant chirurgie versus chimiothérapie après chirurgie). Par conséquent, peu importe ce qui apparaît dans le numérateur du rapport de danger., En utilisant les données de l’exemple 3, le rapport de risque est estimé comme suit:
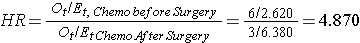
ainsi, le risque de décès est 4.870 fois plus élevé dans le groupe chimiothérapie avant chirurgie que dans le groupe chimiothérapie après chirurgie.
L’exemple 3 a examiné l’association d’une seule variable indépendante (chimiothérapie avant ou après la chirurgie) sur la survie. Cependant, il est souvent intéressant d’évaluer l’association entre plusieurs facteurs de risque, considérés simultanément, et le temps de survie., L’une des techniques de régression les plus populaires pour les résultats de survie est l’analyse de régression des risques proportionnels de Cox. Il existe plusieurs hypothèses importantes pour une utilisation appropriée du modèle de régression des risques proportionnels de Cox, y compris
- l’indépendance des temps de survie entre les individus distincts de l’échantillon,
- une relation multiplicative entre les prédicteurs et le danger (par opposition à une relation linéaire comme c’était le cas avec l’analyse de régression linéaire multiple, discutée plus en détail ci-dessous), et
- un rapport de risque constant au fil du temps.,
le modèle de régression des dangers proportionnels de Cox peut s’écrire comme suit:
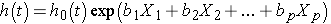
où h(t) est le danger attendu au temps t, h0(t) est le danger de base et représente le danger danger lorsque tous les prédicteurs (ou variables indépendantes) X1, X2 , XP sont égaux à zéro. Notez que le danger prédit (c.-À-D. h (t)), ou le taux de souffrance de l’événement d’intérêt à l’instant suivant, est le produit du danger de base (h0(t)) et de la fonction exponentielle de la combinaison linéaire des prédicteurs., Ainsi, les prédicteurs ont un effet multiplicatif ou proportionnel sur le danger prédit.
Considérons un modèle simple avec un prédicteur, X1., Le modèle de risques proportionnels de Cox est:
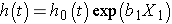
parfois, le modèle est exprimé différemment, reliant le danger relatif, qui est le rapport du danger au temps t au danger de base, aux facteurs de risque:
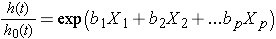
Nous pouvons prendre le logarithme naturel (Ln) de chaque côté du modèle de régression des risques proportionnels de Cox, pour produire ce qui suit qui relie le log du risque relatif à une fonction linéaire des prédicteurs., Notez que le côté droit de l’équation ressemble à la combinaison linéaire plus familière des prédicteurs ou des facteurs de risque (comme on le voit dans le modèle de régression linéaire multiple).
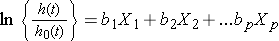
Dans la pratique, l’intérêt réside dans les associations entre les facteurs de risque ou des facteurs prédictifs (X1, X2, …, Xp) et le résultat. Les associations sont quantifiées par les coefficients de régression coefficients (b1, b2, …, bp)., La technique d’estimation des coefficients de régression dans un modèle de régression des risques proportionnels de Cox dépasse le cadre du présent texte et est décrite dans Cox et Oakes.9 nous nous concentrons Ici sur l’interprétation. Les coefficients estimés dans le modèle de régression des risques proportionnels de Cox, b1, par exemple, représentent la variation du logarithme attendu du rapport des risques par rapport à une variation d’une unité dans X1, en maintenant tous les autres prédicteurs constants.
l’antilog d’un coefficient de régression estimé, exp(bi), produit un rapport de danger. Si un prédicteur est dichotomique (par exemple,, X1 est un indicateur de maladie cardiovasculaire répandue ou de sexe masculin) puis exp (b1) est le rapport de risque comparant le risque d’événement pour les participants avec X1=1 (par exemple, maladie cardiovasculaire répandue ou sexe masculin) aux participants avec X1=0 (par exemple, sans maladie cardiovasculaire ou sexe féminin).
Si le rapport de risque pour un prédicteur est proche de 1, ce prédicteur n’affecte pas la survie. Si le rapport de danger est inférieur à 1, le prédicteur est protecteur (c.-à-d.,, associée à une amélioration de la survie) et si le rapport de danger est supérieur à 1, alors le prédicteur est associé à un risque accru (ou à une diminution de la survie).
Les Tests d’hypothèse sont utilisés pour évaluer s’il existe des associations statistiquement significatives entre les prédicteurs et le temps d’événement. Les exemples qui suivent illustrent ces tests et leur interprétation.
le modèle proportionnel des dangers de Cox est appelé modèle semi-paramétrique, car il n’y a pas d’hypothèses sur la forme de la fonction de danger de base. Il y a cependant d’autres hypothèses comme indiqué ci-dessus (c’est à dire,, l’indépendance, les changements dans les prédicteurs produisent des changements proportionnels dans le danger indépendamment du temps, et une association linéaire entre le logarithme naturel du danger relatif et les prédicteurs). Il existe d’autres modèles de régression utilisés dans l’analyse de la survie qui supposent des distributions spécifiques pour les temps de survie telles que les distributions exponentielles, Weibull, Gompertz et log-normales 1,8. Le modèle de survie par régression exponentielle, par exemple, suppose que la fonction de danger est constante., D’autres distributions supposent que le danger augmente au fil du temps, diminue au fil du temps ou augmente initialement puis diminue. L’exemple 5 illustre l’estimation d’un modèle de régression des risques proportionnels de Cox et traite de l’interprétation des coefficients de régression.
exemple:
Une analyse est effectuée pour étudier les différences de mortalité toutes causes confondues entre les hommes et les femmes participant à L’étude Framingham Heart en fonction de l’âge. Un total de 5 180 participants âgés de 45 ans et plus sont suivis jusqu’au moment du décès ou jusqu’à 10 ans, selon la première éventualité., Quarante-six pour cent de l’échantillon sont des hommes, la moyenne d’âge de l’échantillon est de 56,8 ans (écart-type = 8.0 ans) et l’âge varie de 45 à 82 ans au début de l’étude. Il y a un total de décès 402 observés parmi les participants 5,180. Des statistiques descriptives sont présentées ci-dessous sur l’âge et le sexe des participants au début de l’étude, classés selon qu’ils décèdent ou non au cours de la période de suivi.,
|
|
Die (n=402) |
Do Not Die (n=4778) |
|---|---|---|
|
Mean (SD) Age, years |
65.6 (8.7) |
56.1 (7.,5) |
|
N (%) Hommes |
221 (55%) |
2145 (45%) |
Nous avons maintenant une estimation de risques proportionnels de Cox modèle de régression et portent un indicateur de sexe masculin et l’âge, en années, à l’heure de la mort. Les estimations des paramètres sont générées dans SAS à l’aide de la procédure de régression des risques proportionnels SAS Cox12 et sont présentées ci-dessous avec leurs valeurs p.,
|
Risk Factor |
Parameter Estimate |
P-Value |
|---|---|---|
|
Age, years |
0.11149 |
0.0001 |
|
Male Sex |
0.,67958 |
0.0001 |
notez qu’il existe une association positive entre l’âge et la mortalité toutes causes confondues et entre le sexe masculin et la mortalité toutes causes confondues (c.-à-d., il y a un risque accru de décès pour les participants plus âgés et pour les hommes).
encore une fois, les estimations des paramètres représentent l’augmentation du log attendu du risque relatif pour chaque augmentation d’une unité du prédicteur, en maintenant les autres prédicteurs constants. Il y a un 0.,11149 augmentation unitaire du logarithme attendu du risque relatif pour chaque année d’augmentation de l’âge, à sexe constant, et une augmentation unitaire de 0,67958 du logarithme attendu du risque relatif pour les hommes par rapport aux femmes, à Âge constant.
pour l’interprétabilité, nous calculons les rapports de danger en exponentiant les estimations des paramètres. Pour l’âge, exp (0,11149) = 1,118. Il y a une augmentation de 11,8% du risque attendu par rapport à une augmentation d’un an de l’âge (ou le risque attendu est 1,12 fois plus élevé chez une personne qui a un an de plus qu’une autre), en gardant le sexe constant. De même, exp (0,67958) = 1.,973. Le risque attendu est 1.973 fois plus élevé chez les hommes que chez les femmes, en maintenant l’âge constant.
supposons que nous considérions d’autres facteurs de risque pour la mortalité toutes causes confondues et que nous estimions un modèle de régression des risques proportionnels de Cox reliant un ensemble élargi de facteurs de risque au temps avant le décès. Les estimations des paramètres sont à nouveau générées dans SAS à l’aide de la procédure de régression des risques proportionnels SAS Cox et sont présentées ci-dessous avec leurs valeurs p.12 sont également inclus ci-dessous les rapports de danger ainsi que leurs intervalles de confiance de 95%.,
Toutes les estimations des paramètres sont estimées en tenant compte des autres prédicteurs. Après avoir pris en compte l’âge, le sexe, la pression artérielle et le statut tabagique, il n’existe aucune association statistiquement significative entre le cholestérol sérique total et la mortalité toutes causes confondues ni entre le diabète et la mortalité toutes causes confondues. Cela ne veut pas dire que ces facteurs de risque ne sont pas associés à la mortalité toutes causes confondues; leur manque d’importance est probablement dû à une confusion (interrelations entre les facteurs de risque considérés). Notez que pour les facteurs de risque statistiquement significatifs (c.-à-d.,, l’âge, le sexe, la pression artérielle systolique et le statut tabagique actuel), que les intervalles de confiance de 95% pour les rapports de danger n’incluent pas 1 (la valeur nulle). En revanche, les intervalles de confiance de 95% pour les facteurs de risque non significatifs (cholestérol sérique total et diabète) incluent la valeur nulle.
exemple:
Une étude de cohorte prospective est menée pour évaluer l’association entre l’indice de masse corporelle et le temps avant la survenue d’une maladie cardiovasculaire (MCV). À l’inclusion, l’indice de masse corporelle des participants est mesuré avec d’autres facteurs de risque cliniques connus de maladie cardiovasculaire (p. ex.,, âge, sexe, tension artérielle). Les Participants sont suivis jusqu’à 10 ans pour le développement de MCV. Dans l’étude de n = 3 937 participants, 543 développent une MCV pendant la période d’observation de l’étude. Dans une analyse de régression des risques proportionnels de Cox, nous trouvons l’association entre L’IMC et le temps à la MCV statistiquement significative avec une estimation des paramètres de 0,02312 (p=0,0175) par rapport à une variation d’une unité de L’IMC.
Si nous exponentions l’estimation des paramètres, nous avons un rapport de danger de 1,023 avec un intervalle de confiance de (1,004-1,043)., Étant donné que nous modélisons L’IMC comme un prédicteur continu, l’interprétation du rapport de risque pour les MCV est relative à une variation d’une unité de L’IMC (l’IMC de rappel est mesuré comme le rapport entre le poids en kilogrammes et la taille en mètres carrés). Une augmentation d’une unité de L’IMC est associée à une augmentation de 2,3% du danger attendu.
pour faciliter l’interprétation, supposons que nous créions 3 catégories de poids définies par L’IMC du participant.
- Le poids Normal est défini comme IMC< 25,0,
- En surpoids comme IMC compris entre 25,0 et 29,9 et
- obèse comme IMC supérieur à 29,9.,
dans l’échantillon, il y a 1 651 (42%) participants qui répondent à la définition du poids normal, 1 648 (42%) qui répondent à la définition du surpoids et 638 (16%) qui répondent à la définition de l’obésité. Le nombre d’événements MCV dans chacun des 3 groupes est indiqué ci-dessous.,
|
Group |
Number of Participants |
Number (%) of CVD Events |
|---|---|---|
|
Normal Weight |
1651 |
202 (12.,2%) |
|
Overweight |
1648 |
241 (14.6%) |
|
Obese |
638 |
100 (15.7%) |
The incidence of CVD is higher in participants classified as overweight and obese as compared to participants of normal weight.,
Nous utilisons maintenant l’analyse de régression des risques proportionnels de Cox pour utiliser au maximum les données sur tous les participants à l’étude. Le tableau suivant présente les estimations des paramètres, les valeurs p, Les rapports de danger et les intervalles de confiance à 95% pour les rapports de danger lorsque nous considérons les groupes de poids seuls (modèle non ajusté), lorsque nous ajustons pour l’âge et le sexe et lorsque nous ajustons pour l’âge, le sexe et d’autres facteurs de risque
Les deux derniers modèles sont des modèles multivariables et sont effectués pour évaluer l’association entre le poids et l’ajustement des MCV incidents pour les facteurs de confusion., Parce que nous avons trois groupes de poids, nous avons besoin de deux variables nominales ou variables indicatrices pour représenter les trois groupes. Dans les modèles, nous incluons les indicateurs de surpoids et d’obésité et considérons le poids normal comme le groupe de référence.
* ajusté en fonction de l’âge, du sexe, de la pression artérielle systolique, du traitement de l’hypertension, de l’état tabagique actuel, du cholestérol sérique total.
dans le modèle non ajusté, il y a un risque accru de MCV chez les participants en surpoids par rapport au poids normal et chez les participants obèses par rapport au poids normal (rapports de danger de 1,215 et 1.,310, respectivement). Cependant, après ajustement en fonction de l’âge et du sexe, il n’y a pas de différence statistiquement significative entre les participants en surpoids et les participants de poids normal en termes de risque de MCV (hazard ratio = 1.067, p=0.5038). La même chose est vraie dans le modèle d’ajustement pour l’âge, le sexe et les facteurs de risque cliniques. Cependant, après ajustement, la différence de risque de MCV entre les participants obèses et les participants de poids normal reste statistiquement significative, avec une augmentation d’environ 30% du risque de MCV chez les participants obèses par rapport aux participants de poids normal.,
retour haut de page | page précédente | page suivante