qu’est-ce que L’Architecture de réseau neuronal convolutionnel?
Cet article a été publié dans le cadre du Blogathon sur la science des données.
Introduction
travailler sur un projet de reconnaissance d’images ou de détection D’objets mais ne pas avoir les bases pour construire une architecture?,
dans cet article, nous allons voir ce que sont les architectures de réseaux neuronaux convolutionnels dès basic et nous prendrons une architecture de base comme étude de cas pour appliquer nos apprentissages, la seule condition préalable est que vous ayez juste besoin de savoir comment fonctionne la convolution mais ne vous inquiétez pas, c’est très simple !!
prenons un simple réseau de neurones à Convolution,
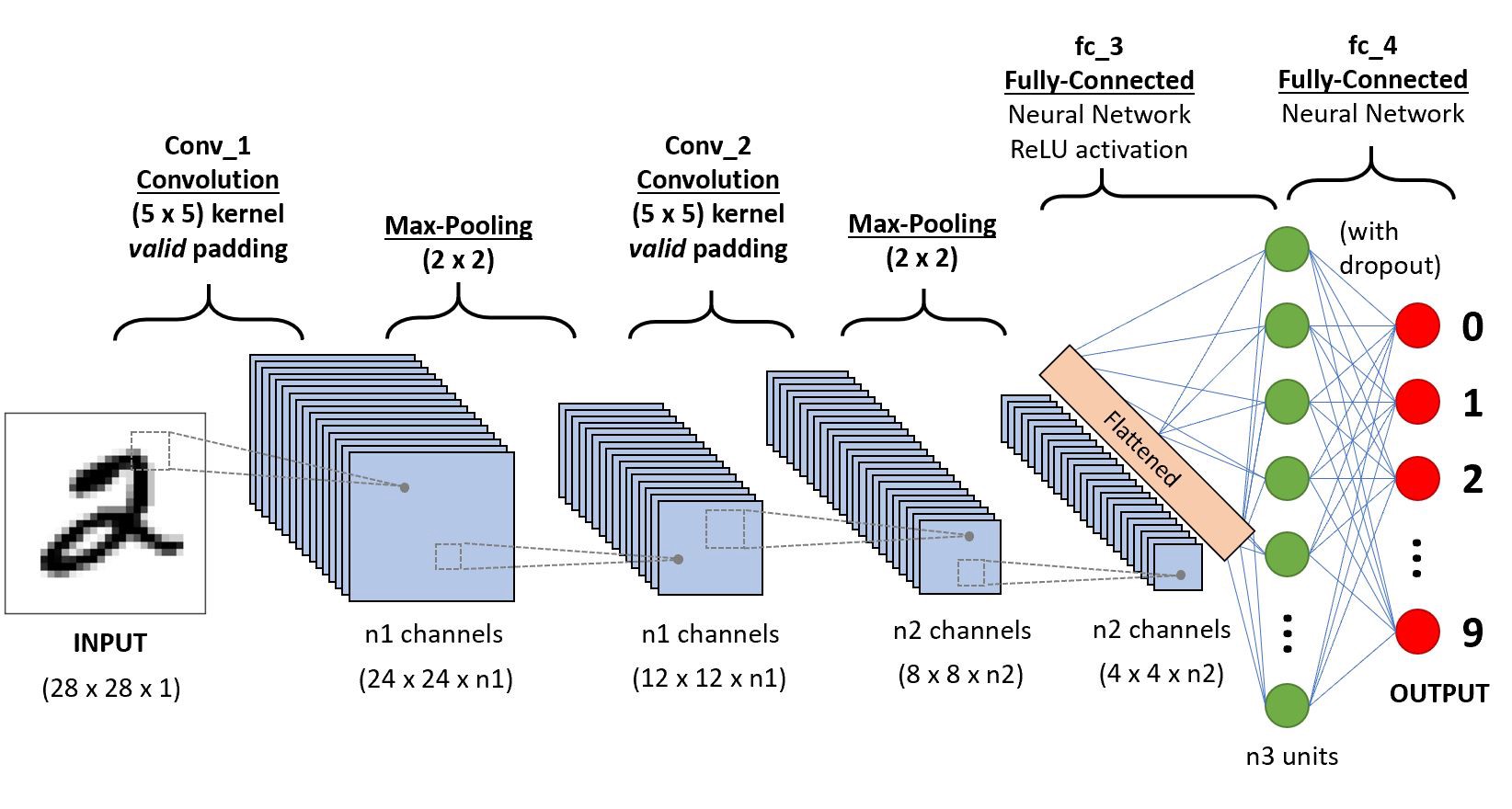
Nous irons couche-sage d’obtenir des informations approfondies sur ce CNN.,
Tout d’abord, il y a quelques choses à apprendre de la couche 1 qui est striding et padding, nous allons voir chacun d’eux en bref avec des exemples
Supposons ceci dans la matrice d’entrée de 5×5 et un filtre de matrice 3X3, pour ceux qui ne savent pas ce qu’est un filtre un ensemble de poids dans une matrice appliquée sur une image ou une matrice pour obtenir les caractéristiques requises, veuillez rechercher sur convolution si c’est votre première fois!
Remarque: Nous prenons toujours la somme ou la moyenne de toutes les valeurs lors d’une convolution.,
Un filtre peut être de n’importe quelle profondeur, si un filtre est d’avoir une profondeur d il peut aller jusqu’à une profondeur de d des couches et spire j’., »f4a6da248a »>
ici, l’entrée est de taille 5×5 Après avoir appliqué un noyau 3×3 ou des filtres, vous obtenez une carte de fonctionnalités de sortie 3×3, essayons donc de formuler ceci
.png)
donc la hauteur de sortie est formulée et la même avec la largeur o/p également
padding
en appliquant des convolutions, nous n’obtiendrons pas les dimensions de sortie les mêmes que celles d’entrée, nous perdrons des données sur les bordures, nous ajoutons donc une bordure de zéros et recalculons,r largeur aussi
Utilisation
parfois, nous ne voulons pas de capturer toutes les données ou informations disponibles, afin de nous ignorer certaines cellules voisines laissez-nous le visualiser,
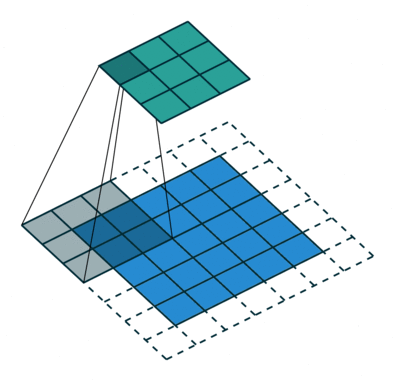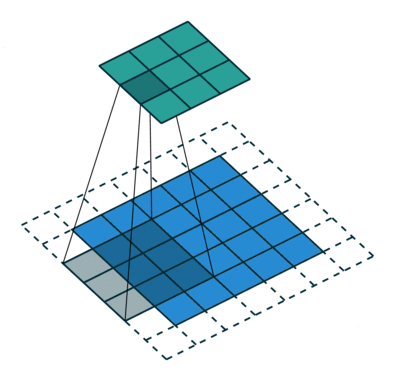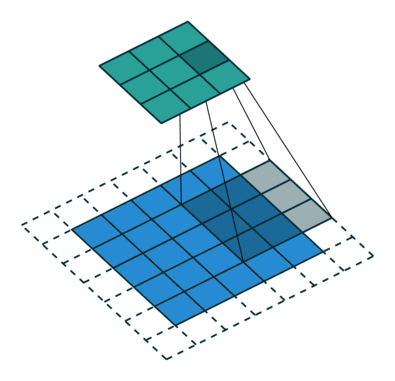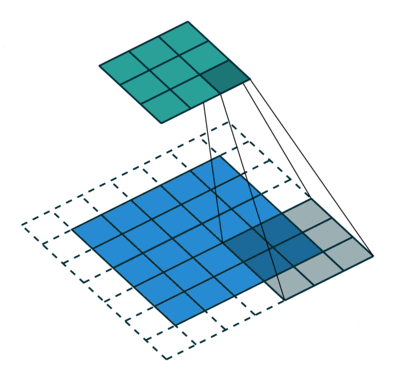
Ici, la matrice d’entrée ou de l’image est de dimensions 5×5 avec un filtre de 3×3 et une foulée de 2 de sorte que chaque fois que nous sauter deux colonnes et de spire, laissez-nous formuler ceci
.png)
Si les dimensions sont en float, vous pouvez prendre ceil() sur la sortie je.,e (next close integer)
ici H fait référence à la hauteur, donc la hauteur de sortie est formulée et la même chose avec la largeur o / p également et ici 2 est la valeur de la foulée afin que vous puissiez la faire comme S dans les formules.
Pooling
en termes généraux, le pooling fait référence à une petite partie, donc ici nous prenons une petite partie de l’entrée et essayons de prendre la valeur moyenne appelée pool moyen ou de prendre une valeur maximale appelée max pooling, donc en faisant le pooling sur une image, nous ne prenons pas toutes les valeurs, nous prenons une valeur résumée sur toutes les valeurs présentes !!!,

Voici un exemple de pooling max donc ici, en prenant une foulée de deux, nous prenons la valeur maximale présente dans la matrice
fonction D’Activation
la fonction d’activation est un nœud placé à la fin ou entre les réseaux de neurones. Ils aident à décider si le neurone se déclencherait ou non., Nous avons différents types de fonctions d’activation comme dans la figure ci-dessus, mais pour ce post, mon accent sera mis sur L’unité linéaire rectifiée (ReLU)
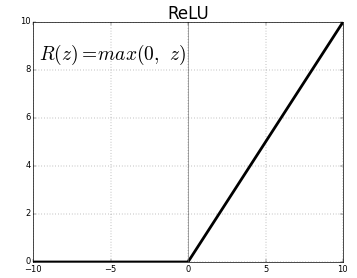
Ne laissez pas tomber vos mâchoires, ce n’est pas complexe cette fonction renvoie simplement 0 si votre valeur est négative sinon elle renvoie la même valeur que vous avez donnée, rien d’autre que d’éliminer les sorties négatives et de maintenir des valeurs entre 0 et +Infinity
maintenant, que nous avons appris toutes les bases nécessaires étudions un réseau neuronal de base appelé lenet.,
LeNet-5
avant de commencer, nous verrons quelles sont les architectures conçues à ce jour.,ures
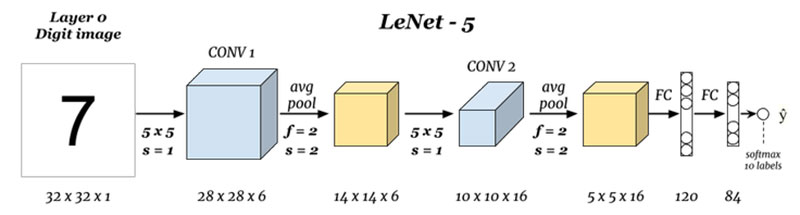
quelles sont les entrées et sorties (couche 0 et couche N) :
ici, nous prédisons des chiffres en fonction de l’image d’entrée donnée, notez qu’ici l’image est de dimensions Height = 32 pixels, width = 32 pixels et une profondeur de 1, Nous pouvons donc supposer qu’il s’agit d’une image en niveaux de gris ou en noir et blanc, en gardant à l’esprit que la sortie est un softmax de toutes les 10 valeurs, ici softmax donne des probabilités ou des rapports pour tous les 10 chiffres, nous pouvons,ef5″>
ici, nous prenons l’entrée et convoluons avec des filtres de taille 5 x 5 produisant ainsi une sortie de taille 28 x 28 vérifiez la formule ci-dessus pour calculer les dimensions de sortie, la chose ici est que nous avons pris 6 tels filtres et donc la profondeur de conv1 est 6, d’où ses dimensions étaient, 28 x 28 x 6 1d4095b07b »>.png)
ici, nous prenons les 28 x 28 x 6 en entrée et appliquons la mise en commun moyenne D’une matrice de 2×2 et d’une foulée de 2 I.,e en survolant une matrice 2 x 2 sur l’entrée et en prenant la moyenne de tous ces quatre pixels et en sautant avec un saut de 2 colonnes à chaque fois donnant ainsi 14 x 14 x 6 comme sortie nous calculons la mise en commun pour chaque couche donc ici la profondeur de sortie est de 6
Convolution 2 (couche 3) :
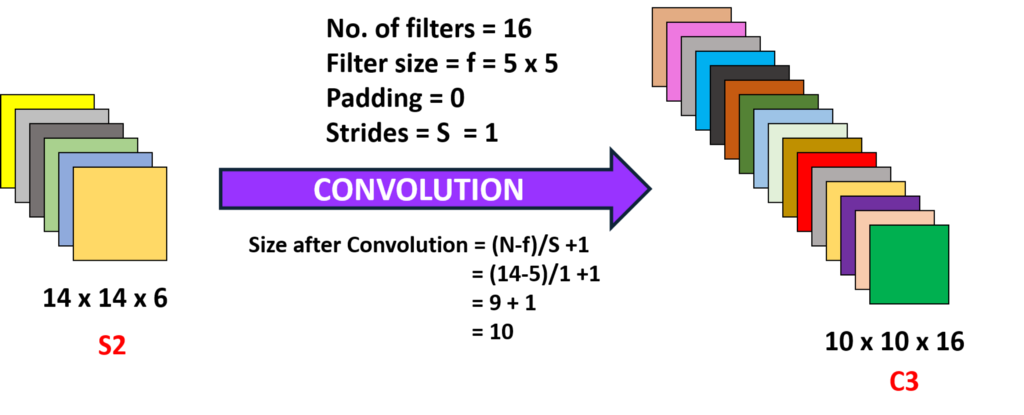
ici, nous prenons le 14 x 14 x 6, c’est-à-dire le précédent O / P et convoluons avec un filtre de taille 5 x5, avec une foulée de 1 I.,e (pas de saut), et avec zéro paddings nous obtenons donc un 10 x 10 sortie, maintenant, ici, nous prenons 16 filtres de profondeur 6 et convoluant ainsi l’obtention d’une puissance de 10 x 10 x 16
mise en commun 2 (Couche 4):

Ici, nous prenons la sortie de la couche précédente et en effectuant la moyenne de mise en commun avec un pas de 2 je.,yer (N-1) :
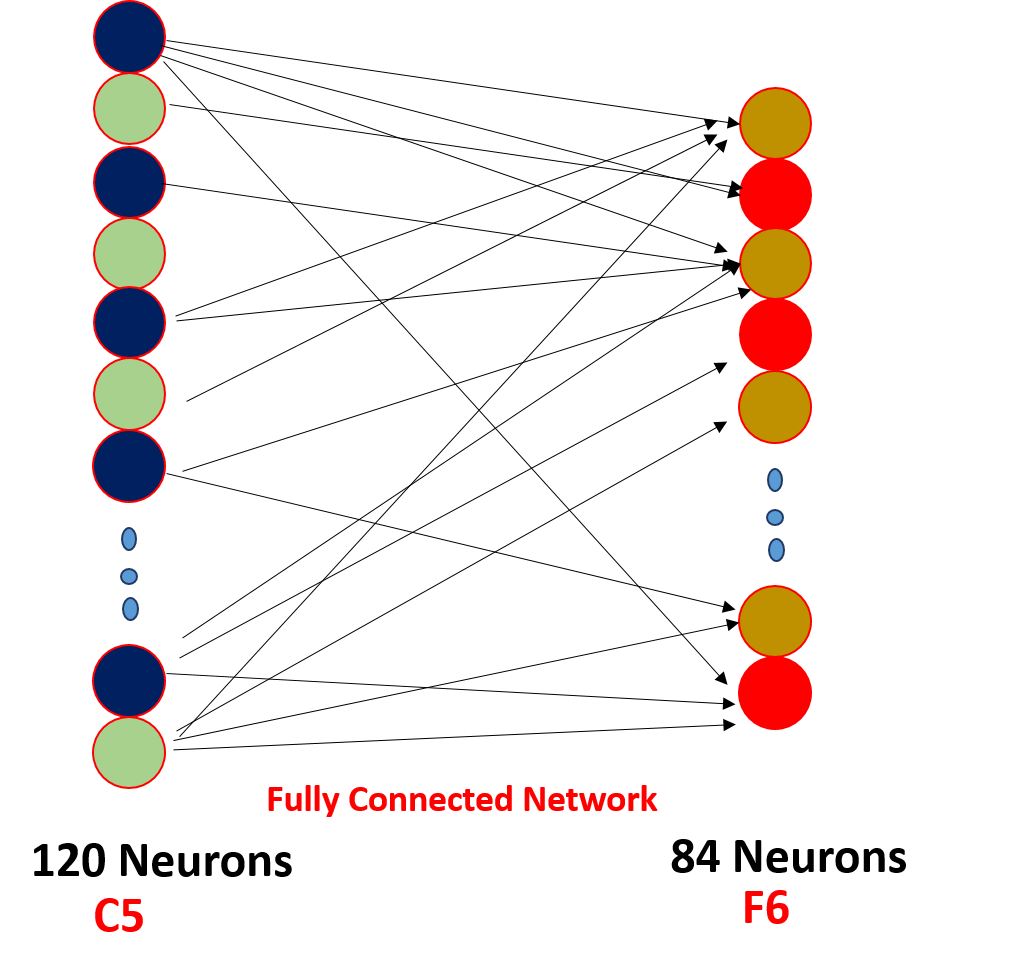
enfin, nous aplatissons tous les 5 x 5 x 16 en une seule couche de valeurs de taille 400 et les entrons dans un réseau neuronal d’alimentation de 120 neurones ayant une matrice de poids de taille et une couche cachée de 84 neurones reliés par les 120 neurones ayant une matrice de poids de et ces 84 neurones sont en effet reliés à une sortie de 10 neurones
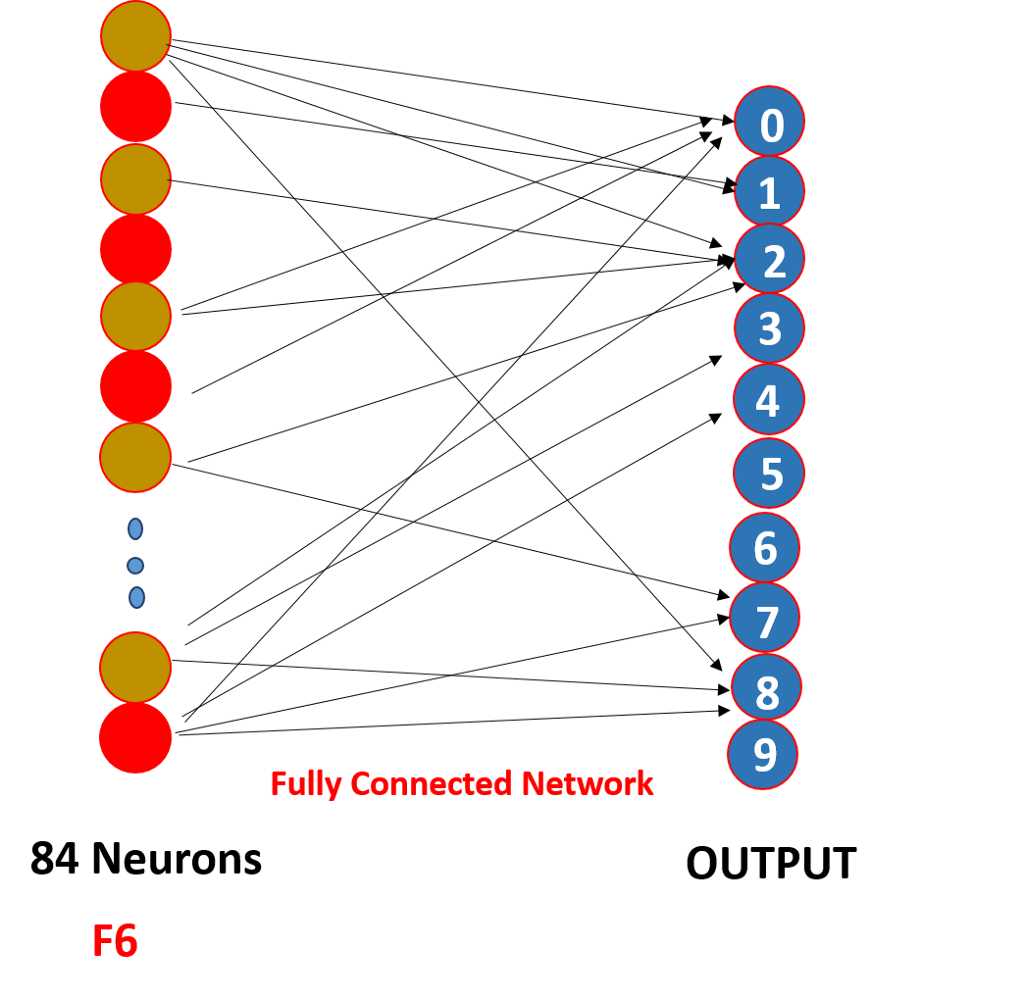
ces neurones O/P finalisent le nombre prédit par softmaxing .,
comment fonctionne réellement un réseau de neurones convolutifs?,
cela fonctionne grâce au partage de poids et à une connectivité clairsemée,
.png)
donc ici, comme vous pouvez le voir, la convolution a des poids ces poids sont partagés par tous les neurones d’Entrée, pas chacun l’entrée a un poids séparé appelé partage de poids, et tous les neurones d’entrée ne sont pas connectés au neurone de sortie a’o seuls certains qui sont alambiqués sont déclenchés connu sous le nom de connectivité clairsemée, CNN n’est pas différent des réseaux de neurones Feed-forward ces deux propriétés les rendent spéciaux !!!,
les Points à regarder
1. Après chaque convolution la sortie est envoyée à une fonction d’activation afin d’obtenir de meilleures caractéristiques et de maintenir la positivité par exemple: ReLu
2. La connectivité clairsemée et le partage de poids sont la principale raison pour laquelle un réseau neuronal convolutif fonctionne
3. Le concept de choisir un certain nombre de filtres entre les couches et le rembourrage et les dimensions de la foulée et du filtre est pris pour faire un certain nombre d’expérimentations, ne vous inquiétez pas de cela, concentrez-vous sur la construction de fondations, un jour vous ferez ces expériences et en construirez une plus productive!!!,
Vous pouvez également lire cet article sur notre APPLICATION Mobile![]()
