Diszperzió / diszperzió mértéke: meghatározás
statisztikai meghatározások > diszperzió
mi a diszperzió?
diszperzió statisztika egy módja annak, hogy leírja, hogyan terjedt el egy sor adat. Ha egy adatkészletnek nagy értéke van, a készlet értékei széles körben szétszóródnak; ha kicsi, a készletben lévő elemek szorosan csoportosulnak., Nagyon alapvetően ez az adatkészlet kis értékkel rendelkezik:
1, 2, 2, 3, 3, 4
… Ez a készlet szélesebb:
0, 1, 20, 30, 40, 100
az adathalmaz elterjedését leíró statisztikák sora írja le, beleértve a varianciát, a szórást és az interkvartilis tartományt. A szórás grafikonokon is megjeleníthető: a dot-parcellák, a boxplotok, valamint a szár-és leveles parcellák nagyobb távolsággal rendelkeznek a nagyobb szórású mintákkal, és fordítva.
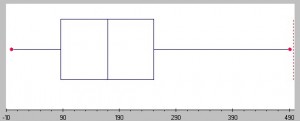
minél nagyobb a doboz, annál nagyobb a diszperzió egy adatkészletben., Kép: Seton Hall University
diszperziós intézkedések.
- diszperziós együttható: a” catch-all ” kifejezés a különböző képletek, beleértve a távolság quartiles.
- szórás: valószínűleg a leggyakoribb intézkedés. Megmutatja, hogy a számok eloszlása a diszperzió átlagos,
- indexéből származik: a névleges változókkal általánosan használt diszperzió mértéke.
- Interquartile range (IQR): leírja, hogy az adatok nagy része hol fekszik (a “középső ötven” százalék).,
- Interdecile tartomány: az első decile (10%) és az utolsó decile (90%) közötti különbség.
- tartomány: a különbség a legkisebb és a legnagyobb szám között egy adatkészletben.
- átlagos különbség vagy különbség az eszközökben: a klinikai vizsgálatok során két különböző csoportban méri a középérték abszolút különbségét.
- medián abszolút eltérés( MAD): az abszolút eltérések medián értéke az adathalmaz medián értékétől.
- Quartiles: Numbers that split the data into four quartiles (first, second, third, and fourth quartiles).,
egyes folyamatokban, mint például a gyártás vagy a mérés, az alacsony diszperzió nagy pontossággal társul. A nagy diszperzió alacsony pontossággal társul.
diszperziós intézkedések: példa
tegyük fel, hogy felkérték Önt, hogy hasonlítsa össze a diszperziós méréseket két adatkészlethez. Az A adathalmaz 97,98,99,100,101,102,103, A B adathalmaz pedig 70,80,90,100,110,120,130 tételekkel rendelkezik. Az adathalmazokat vizsgálva valószínűleg azt lehet mondani, hogy az eszközök és a medikusok ugyanazok (100), amelyeket technikailag “központi tendenciának” neveznek a statisztikákban.,
azonban a tartomány (amely képet ad arról, hogy a teljes adatkészlet hogyan oszlik el) sokkal nagyobb a B (60) adatkészlet esetében, mint az a (6) adatkészlet. Valójában szinte minden diszperziós intézkedés tízszer nagyobb lenne a B adatkészletnél, ami értelme, mivel a tartomány tízszer nagyobb. Vessen egy pillantást például a két adatkészlet szórására:
Standard deviáció A: 2.160246899469287.
Standard deviáció B: 21.602468994692867.
A B adathalmaz értéke pontosan tízszerese az A-nak.,
figyelmeztetés: számológép (vagy képlet) használatakor ellenőrizze, hogy az adatok megfelelő beállítását (vagy képletét) használja-e. Számos diszperziós intézkedés (mint például a variancia) két különböző képlettel rendelkezik, az egyik egy populációra, a másik pedig egy mintára. Ha nem biztos benne, hogy van-e minta vagy népesség, olvassa el ezeket a cikkeket:
Mi a népesség a statisztikákban?
minta a statisztikákban: mi az, hogyan lehet megtalálni.
nézze meg statisztikáinkat YouTube csatorna., Több száz alapvető videók egy sor elemi statisztikai témák.
——————————————————————————
segítségre van szüksége egy házi feladathoz vagy tesztkérdéshez? A Chegg tanulmány segítségével lépésről-lépésre megoldásokat kaphat kérdéseire a terület szakértőjétől. Az első 30 perc egy Chegg oktatóval ingyenes!