Cox Proportional Hazards 회귀 분석을
생존분석 방법을 확장할 수 있습을 평가하는 여러 가지 위험 요인 동시에 유사한 여러 선형 및 다중 로지스틱 회귀 분석으로 설명에서 모듈을 논의 혼란,효과정,상관관계,그리고 다변수 방법이 있습니다. 가장 인기있는 중 하나 회귀 기술을 위한 생존분석은 Cox proportional hazards 회귀하는 데 사용되는 관련된 여러 가지 위험 요인이나 노출로 간주는 동시에,생존 시간입니다., 에 Cox proportional hazards 회귀분석 모델의 측정 결과는 위험 평가,는 실패의 위험이(즉,위험 또는 확률통의 관련 이벤트),주어진 참가자는 살아까지 특정 시간입니다. 확률은 0 에서 1 까지의 범위에 있어야합니다. 그러나 위험은 한 단위 시간당 예상되는 이벤트 수를 나타냅니다. 결과적으로 그룹의 위험은 1 을 초과 할 수 있습니다. 는 경우,예를 들어,위험 0.2 시간 및 시간 단위가 개월 동안,그 다음에 평균,0.2 이벤트가 예상되는 인당에서 위험습니다., 또 다른 해석은 위험의 상호에 기초한다. 예를 들어,1/0.2=5 는 위험에 처한 사람당 예상되는 이벤트없는 시간(5 개월)입니다.
대부분의 상황에서,우리가 관심을 비교에 대해 그룹의 위험성과 우리가 사용하여 위험 비율은 유사하는 확률은 비율의 설정에서 다중 로지스틱 회귀 분석한다. 위험 비율은 로그 순위 테스트를 수행하기 위해 우리가 구성하는 데이터에서 추정 할 수 있습니다., 특히,위험 비율의 비율의 총수는 관찰을 수상하는 이벤트에서 두 개의 독립적인 비교 groups:

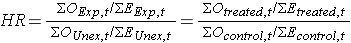
일부 연구에서,차이점을 노출하거나 치료에 비해 노출되지 않거나 control 그룹은 명확하다. 다른 연구에서는 그렇지 않습니다., 후자의 경우에,그룹 중 하나를 나타날 수 있습에서 분자와 해석의 위험 비율은 후 위험의 이벤트에 그룹에서는 분자에 비하여 위험의 이벤트에 그룹 여러 분야에 사용됩니다.
실시예 3 에서는 두 가지 활성 치료법이 비교되고 있다(수술 전 화학요법 대 수술 후 화학요법). 결과적으로 위험 비율의 분자에 어느 것이 나타나는지는 중요하지 않습니다., 의 데이터를 사용하여 예를 들어,3,위험 비율로 추정된다:
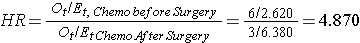
따라서,죽음의 위험 4.870 시간에 높은 항암화학요법은 수술 전에 그룹에 비해 화학요법 수술 후 그룹입니다.
실시예 3 은 생존에 대한 단일 독립 변수(수술 전 또는 수술 후 화학 요법)의 연관성을 조사했다. 그러나 동시에 고려되는 여러 위험 요소와 생존 시간 사이의 연관성을 평가하는 것이 종종 관심사입니다., 생존 결과를위한 가장 보편적 인 회귀 기법 중 하나는 콕스 비례 위험 회귀 분석입니다. 거기에 몇 가지 중요한 가정의 적절한 사용에 대한 Cox proportional hazards 회귀분석 모델에 포함
- 독립의 생존 시간 간의 뚜렷한 개인 샘플
- 배수 간의 관계를 예측하고 위험(반대로 선형 중 하나의 경우와 같이 여러 선형 회귀분석,자세히 설명 아래),그리고
- 상수 위험 비율을 통해 시간.,
Cox proportional hazards 회귀분석 모델은 다음과 같이 작성할 수 있습니다:
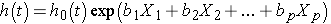
어디서(t)는 예상된 위험에서 시간 t,h0(t) 기준의 위험을 나타냅 위험할 때 모든 예언자(또는 독립 변수)X1,X2,Xp 에서 동일한다. 통지는 예상된 위험을(즉,h(t)),또는 비율의 고통의 관심사에서는 다음을 인스턴트,제품의 위험을 기준(h0(t))과 지수 함수의 선형 조합의 예측., 따라서 예측 변수는 예측 된 위험에 곱셈 적 또는 비례 적 영향을 미칩니다.
하나의 예측 변수 인 X1 을 가진 간단한 모델을 고려하십시오., Cox proportional hazards model:
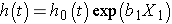
때로는 이 모델은 다르게 표현에 관한 상대적인 위험,이는 비율의 위험에 시간을 기준 위험,위험 요인:
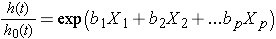
을 취할 수있는 자연 로그(ln)의 각 측면의 Cox proportional hazards 회귀분석 모델을 생산하기 위해,다음과 관련된 로그의 상대적 위험성 선형의 기능을 예측., 지 오른쪽 방정식의 것 같은 더 친숙한 선형의 조합을 예측변수나 위험 요소(에서 볼 수 있듯이 여러 linear regression model).
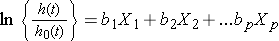
연습,관심 사이의 연관의 각각의 위험 요인이나 예측(X1,X2,…,Xp)및 결과. 연관성은 회귀 계수 계수(b1,b2,…,bp)., Cox 비례 위험 회귀 모델에서 회귀 계수를 추정하는 기술은이 텍스트의 범위를 벗어나며 Cox 및 Oakes 에 설명되어 있습니다.9 여기서 우리는 해석에 중점을 둡니다. 예상 계수 Cox proportional hazards 회귀분석 모형,b1,예를 들어,나타내는 변경에서 예상되는 로그의 위험 비율을 기준으로 한 단위에서 변경 X1,을 잡고 모든 다른 예언자 상수입니다.
추정 회귀 계수 인 exp(bi)의 antilog 는 위험 비율을 생성합니다. 예측 변수가 이분법 인 경우(예:, X1 은 지표의 유행이 심혈관 질병 또는 남성 성)다음 exp(b1)은 위험 비율을 비교하의 위험에 대한 이벤트 참가자 X1=1(예를 들어,널리 심장 혈관 질병 또는 남성 성)에 참가자 X1=0(예를 들어,심장 혈관 질병의 무료 또는 여성 성).
예측 변수에 대한 위험 비율이 1 에 가깝다면 그 예측 변수는 생존에 영향을 미치지 않습니다. 위험 비율이 1 보다 작 으면 예측 변수는 보호 적입니다(즉,, 과 관련된 개선된 생존)과하는 경우 위험 비율이 1 보다 크게 다음의 예측과 연관된 위험이 증가(또는 감소 생존).
의 테스트 가설을 사용되는지 여부를 평가 있는 통계적으로 중요한 연결을 예측 사고 시간하는 이벤트입니다. 뒤 따르는 예는 이러한 테스트와 그 해석을 보여줍니다.
Cox 비례 위험 모델은 기준 위험 함수의 모양에 대한 가정이 없기 때문에 반 파라 메트릭 모델이라고합니다. 그러나 위에서 언급 한 것처럼 다른 가정이 있습니다(즉,,,독립성에 변화가 예측 생산하는 비례적인 변화에서 위험 관계없이,시간 및 선형 연결 사이의 자연적인 로그의 상대적 위험 그리고 예측). 다른 회귀분석 모델에 사용된 생존에 분석된 특정 배포판에 대한 생존 시간 등과 같은 지수,Weibull 분포,Gompertz 및 log-일반 distributions1,8. 예를 들어 지수 회귀 생존 모델은 위험 함수가 일정하다고 가정합니다., 다른 분포를 가정하는 위험은 증가하고 시간,시간이 지남에 따라 점점 감소하거나,증가 처음에는 다음이 감소하고 있습니다. 실시예 5 는 콕스 비례 위험 회귀 모델의 추정을 설명하고 회귀 계수의 해석을 논의할 것이다.
예:
는 분석 조사를 실시에 차이가 모든 원인 사망 사이의 남성 및 여성에 참여하는 프레이밍햄 심장 연구를 위한 조정이다. 45 세 이상인 총 5,180 명의 참가자가 사망 한 시점까지 또는 10 세까지 추적되며,어느 것이 먼저 오는지., 표본의 40%는 남성이며 표본의 평균 연령은 56.8 세(표준 편차=8.0 세)이며 연령은 연구 시작시 45 세에서 82 세 사이입니다. 5,180 명의 참가자 중 총 402 명의 사망자가 관찰되었습니다. 설명 통계는 다음과 같 아래에서 나이와 성별 참가자의 시작에서의 연구에 의해 분류되지 그들이 죽거나 죽지 않는 동안에 따라 기간입니다.,
|
|
Die (n=402) |
Do Not Die (n=4778) |
|---|---|---|
|
Mean (SD) Age, years |
65.6 (8.7) |
56.1 (7.,5) |
|
N(%)남 |
221(55%) |
2145(45%) |
우리는 지금 예측 Cox proportional hazards 회귀분석 모델 및 관련된 지시자의 성별과 연령에서는 년간,시간이 죽음입니다. 매개 변수 추정치는 SAS Cox 비례 위험 회귀 절차 12 를 사용하여 SAS 에서 생성되며 p-값과 함께 아래에 표시됩니다.,
|
Risk Factor |
Parameter Estimate |
P-Value |
|---|---|---|
|
Age, years |
0.11149 |
0.0001 |
|
Male Sex |
0.,67958 |
0.0001 |
참고가 있다는 긍정적인 연결이 나와 모든 사망의 원인과 사이의 남성 및 모든 원인의 사망률(즉,거기에 위험을 증가의 죽음에 대한 이전의 참가자들 및 남자를 위한).
다시 매개 변수 추정치를 나타내는 증가가 예상되는 로그의 상대적 위험에 대한 각 단위 증가,예측에서 들고 다른 예언자 상수입니다. 0 이 있습니다.,11149 단위 증가가 예상되는 로그의 상대적 위험에 대한 각 매년 증가에 나이를 들고,성별 일정 및 0.67958 단위 증가가 예상되는 로그의 상대적 위험에 대한 남성에 비해 여자를 들고 나이는 상수입니다.
해석 가능성을 위해 매개 변수 추정치를 지수 화하여 위험 비율을 계산합니다. 나이,경험치(0.11149)=1.118. 있는 11.8%증가가 예상되는 위험이 상대적으로 중년 증가에 나이(또는 예상된 위험 1.12 시간에 더 높은 사람이 일년보다 오래된 다른)들고,성별 일정하다. 마찬가지로 exp(0.67958)=1 입니다.,973. 예상되는 위험은 연령 상수를 유지하면서 여성에 비해 남성에서 1.973 배 더 높습니다.
가정하에 우리는 고려한 추가적인 위험 요소에 대한 모든 원인의 사망률을 추정 Cox proportional hazards 회귀분석 모델에 관한 확장된 위험 요인을 시간이 죽음입니다. 매개 변수 추정치는 SAS Cox 비례 위험 회귀 절차를 사용하여 sas 에서 다시 생성되며 p-값과 함께 아래에 표시됩니다.12 또한 아래에 포함 된 위험 비율은 95%신뢰 구간과 함께 있습니다.,
매개 변수 추정치는 모두 다른 예측 변수를 고려하여 추정됩니다. 후 회계,나이,성별,혈압연 상태에 있는 통계적으로 중요한 연결 사이에는 총 혈중 콜레스테롤과 모든 원인 사망 또는 당뇨병과 모든 원인 사망. 이것은 말하지 않는 이러한 위험 요인과 연결되지 않은 모든 원인 사망,그들의 부족을 의미를 가능성이 높으로 인하여 혼동(사이의 상호 관계에 위험 요인을 고려). 통계적으로 유의미한 위험 요소(즉,,,나이,성별,수축기 혈압 및 현재 흡연 상태)에서는 95%의 신뢰 구간에 대 위험 비율을 포함하지 않 1(null 값). 대조적으로,유의하지 않은 위험 인자(총 혈청 콜레스테롤 및 당뇨병)에 대한 95%신뢰 구간에는 null 값이 포함됩니다.
예:
미래의 코호트 연구가 실행 사이의 연관성을 평가하기 위해 체질량지수와 시간은 사건의 심장 혈관 질병(CVD). 기준,참가자”체질량지수 측정을 따라 다른 알려진 임상 위험 요소에 대한 심장 혈관 질병(예:,,나이,성별,혈압). 참가자는 CVD 개발을 위해 최대 10 년 동안 추적 관찰됩니다. N=3,937 참가자의 연구에서 543 은 연구 관찰 기간 동안 CVD 를 개발합니다. 에 Cox proportional hazards 회귀 분석,우리는 협회를 찾아 사 BMI 와 시간을 CVD 통계적으로 중요한 매개 변수의 추정 0.02312(p=0.0175)기준으로 한 단위에서 변경 BMI.
우리가 매개 변수 추정치를 지수 화하면,우리는(1.004-1.043)의 신뢰 구간으로 1.023 의 위험 비율을 갖습니다., 기 때문에 우리 모델 BMI 으로 지속적인 예측,해석의 위험 비율을 위한 CVD 은 상대적으로 한 단위에서 변경 BMI(리콜 BMI 를 측정한 비율로서의 체중에는 킬로그램을 높이 제곱 미터에서). BMI 의 한 단위 증가는 예상되는 위험의 2.3%증가와 관련이 있습니다.
해석을 용이하게하기 위해 참가자의 BMI 에 의해 정의 된 3 가지 범주의 체중을 생성한다고 가정합니다.
- 정상적인 무게로 정의 BMI<25.0,
- 과체중으로 BMI 사 25.0 29.9,그리고
- 비만으로 BMI 를 초과하 29.9.,
표본에는 정상 체중의 정의를 충족시키는 1,651 명(42%)의 참가자,과체중의 정의를 충족시키는 1,648 명(42%),비만의 정의를 충족시키는 638 명(16%)이 있습니다. 3 개 그룹 각각의 CVD 이벤트 수는 아래와 같습니다.,
|
Group |
Number of Participants |
Number (%) of CVD Events |
|---|---|---|
|
Normal Weight |
1651 |
202 (12.,2%) |
|
Overweight |
1648 |
241 (14.6%) |
|
Obese |
638 |
100 (15.7%) |
The incidence of CVD is higher in participants classified as overweight and obese as compared to participants of normal weight.,
우리는 이제 Cox 비례 위험 회귀 분석을 사용하여 연구의 모든 참가자에 대한 데이터를 최대한 활용합니다. 다음과 같은 테이블을 표시합 매개 변수 추정,p-값 위험 비율은 95%의 신뢰도 간격에 대 위험 비율을 고려할 때 우리는 무게 그룹 혼자(조정되지 않은 모델)을 때,우리는 우리를 조정한 나이와 성을 때 우리는 우리를 조정한 나이,성별 및 다른 알려진 임상 위험 요소에 대한 사건이 표시됩니다.
후자의 두 가지 모델은 다변수 모델은 수행 사이의 연관성을 평가하기 위해 무게 및 사 CVD 조정 confounders., 우리가 가지고 있기 때문에 세 가지는 무게 그룹,우리가 필요한 두 개의 더미변수 또는 지시계 변수를 나타내는 세 개의 그룹입니다. 모델에서 우리는 과체중 및 비만에 대한 지표를 포함하고 정상 체중을 기준 그룹으로 간주합니다.
*조정한 나이,성별,수축기혈압 치료에 대한 고혈압,현재 흡연 상태,총 혈중 콜레스테롤.
에서 조절하지 않은 모델,위험이 증가 심혈관계 질환의 과체중에서는 참가자에 비해 정상적인 무게 및에서 비만으로 정상에 비해 무게 참가자(위험 비율의 1.215 1.,310,각각). 그러나,이후 조정에 대한 연령하고 성이없는,통계적으로 유의한 차이 과체중과 정상적인 무게 참가자의 관점에서 CVD 위험(위험 비율=1.067,p=0.5038). 연령,성별 및 임상 적 위험 요소를 조정하는 모델에서도 마찬가지입니다. 그러나,이후 조정에 차이 CVD 위험이 뚱뚱하고 정상적인 체중을 참가자에 남아 있는 통계적으로 약 30%증가에서의 위험 CVD 사이에서 비만 참가자에 비해 참가자들의 정상적인 무게.,이전 페이지|다음 페이지로 돌아 가기