SPSS 튜토리얼:한 샘플 t 험
문제 문
CDC 에 따르면,높이 평균의 성인 연령 20 세 이상은 대한 66.5 인치(69.3 인치에 대한 남성,63.8 인치한 암컷). 한 샘플 t 테스트를 사용하여 샘플 데이터의 평균 높이가 66.5 인치와 크게 다른지 테스트하십시오. 이 테스트의 null 및 대체 가설은 다음과 같습니다.
여기서 66.5 는 성인의 평균 높이의 CDC”s 추정치이고 xHeight 는 샘플의 평균 높이입니다.,
테스트 전에
샘플 데이터에서 각 응답자의 높이를 인치 단위로 나타내는 연속 변수 인 가변 높이를 사용합니다. 높이 전시 값의 범위에서 55.00 을 88.41(을 분석하는>설명 통계를>기술통계).
하자”들을 만들의 히스토그램 데이터의 아이디어를 얻을 배포,그리고 보면 우리의 가설을 의미 근처의 샘플을 의미합니다. 그래프>레거시 대화 상자>히스토그램을 클릭하십시오., 변수 높이를 변수 상자로 이동 한 다음 확인을 클릭하십시오.
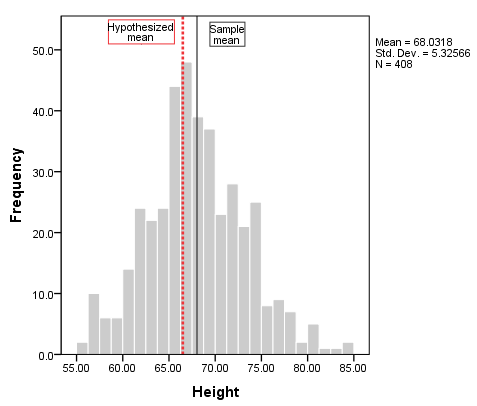
추가 수직 참조 라인에서 의미(또는 다른 위치),더블 클릭하면 그림에게 열 차트 편집기,옵션을 클릭합니다.>X 축 참조 라인입니다. 의 속성에서 창에 입력할 수 있는 특정 위치의 x 축에 수직 라인,또는 당신이 선택할 수 있을 참조 라인에서 평균 또는 평균의 샘플 데이터를(샘플 데이터를 사용하여). 적용을 클릭하여 새 줄이 차트에 추가되었는지 확인하십시오., 여기,우리는 두 가지를 추가 참조선:중 하나에서 샘플을 의미(솔리드 블랙 line),다른에서 66.5(은 빨간색 점선).
히스토그램에서,우리가 볼 수 있는 높은 상대적으로 대칭으로 배에 대해 의미 있지만,약간 긴 바로 꼬리입니다. 참조 선은 샘플 평균이 가설 평균보다 약간 크지 만 엄청난 양이 아님을 나타냅니다. 우리의 테스트 결과가 크게 돌아올 수 있습니다.,
실행하는 테스트
를 실행하는 하나의 샘플 t 테스트,분석을 클릭>비교는 의미는>하나-샘플 T 험합니다. 가변 높이를 테스트 변수 영역으로 이동합니다. 테스트 값 필드에 20 세 이상 성인의 평균 신장에 대한 CDC 의 추정치 인 66.5 를 입력하십시오.

확인을 클릭하여 실행하여 하나의 샘플 t 험합니다.,
Syntax
출력
테이블
두 가지 섹션이(박스)에서 나타나는 출력:중 하나는 샘플링을 통계와 한-샘플 테스트입니다. 첫 번째 섹션 중 하나는 샘플링,통계 기본적인 정보를 제공합,선택한 변수를 높이를 포함하여,유효한(비결측)샘플 크기(n),평균,표준 편차,그리고 표준에 오류가 있습니다. 이 예에서 샘플의 평균 높이는 68.03 인치이며,이는 408 개의 비접촉 관찰을 기반으로합니다.,

두 번째 섹션 중 하나는 샘플링,테스트 결과를 표시합니다 가장 관련성이나 샘플 t 험합니다.

테스트 값:수 우리는 입으로 테스트에 값을 한 샘플 T 테스트 창을 닫으십시오.
B t 통계:t 로 표시된 1 샘플 t 테스트의 테스트 통계입니다.이 예에서는 t=5.810 입니다. T 는 평균 차이(E)를 표준 오차 평균(1 샘플 통계 상자에서)으로 나누어 계산합니다.
C df:시험에 대한 자유도., 1 샘플 t 테스트의 경우 df=n-1;여기서 df=408-1=407 입니다.<피>디 시그. (2 꼬리):시험 통계에 해당하는 2 꼬리 p-값입니다.
E 평균 차이:”관찰 된”샘플 평균(하나의 샘플 통계 상자에서)과”예상”평균(지정된 테스트 값(A))의 차이입니다. 평균 차이의 부호는 t 값(B)의 부호에 해당합니다. 이 예에서 양의 t 값은 샘플의 평균 높이가 가설 값(66.5)보다 크다는 것을 나타냅니다.,
F 차이에 대한 신뢰 구간:지정된 테스트 값과 샘플 평균 사이의 차이에 대한 신뢰 구간입니다.
결정과 결론
이후 p<0.001,우리는 null 가설을 거부하는 표본과 같 가설 인구 평균과 결론을 내는 것을 의미의 높이는 샘플 크게 다른 것보다 평균 높이의 전반적인 성인 인구입니다.,
결과에 기초하여,우리가 할 수 있습 다음과 같다:
- 상당한 차이가 있에서 높이 평균 샘플과 전반적인 성숙한 인(p<.001).
- 샘플의 평균 신장은 전체 성인 인구 평균보다 약 1.5 인치 더 큽니다.