분산/조치의 분산:정의
통계 정의는>분산
무이산?
통계에서의 분산은 일련의 데이터가 얼마나 퍼져 있는지를 설명하는 방법입니다. 데이터 집합에 큰 값이 있으면 집합의 값이 넓게 흩어지며,작은 경우 집합의 항목이 단단히 클러스터됩니다., 매우 기본적으로 이 설정의 데이터가 작은 값:
1, 2, 2, 3, 3, 4
…및 이 설정에는 더 넓은 하나:
0, 1, 20, 30, 40, 100
의 확산 데이터 집합을 설명할 수 있습의 범위에 의해 설명하는 통계 분산을 포함하여,표준 편차,and interquartile range. 확산될 수도 있습에 표시된 그래프:도표,상자 그림,그리고 줄기와 잎 그림이 더 큰 거리와 샘플는 큰 분산과 그 반대입니다.
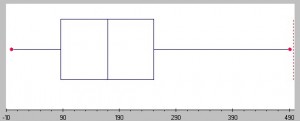
더 큰 박스,더 많은 분산에서 데이터의 세트입니다., 이미지:Seton Hall University
분산 측정.
- 분산 계수:사 분위수 사이의 거리를 포함하여 다양한 수식에 대한”캐치 올”용어.
- 표준 편차:아마도 가장 일반적인 측정 일 것입니다. 그것은 당신을 알려주는 방법을 확산 숫자는 의미에서,
- 인덱스의 분산:산의 특정 일반적으로 사용되는 소액의 변수입니다.
- 쿼터 간 범위(IQR):대량의 데이터가 어디에 있는지 설명합니다(“중간 50″퍼센트).,
- Interdecile 범위:첫 번째 decile(10%)과 마지막 decile(90%)의 차이.
- 범위:데이터 집합에서 가장 작은 숫자와 가장 큰 숫자의 차이입니다.
- 의미 차이나 차이에 의미합니다:측정 절대적인 차이의 평균 값이고에서 두 개의 서로 다른 그룹 임상 시험에서.
- 중앙값 절대 편차(MAD):데이터 세트의 중앙값에서 절대 편차의 중앙값입니다.
- 사 분위수:데이터를 4 분의 1(첫 번째,두 번째,세 번째 및 네 번째 사 분위수)으로 분할하는 숫자입니다.,
제조 또는 측정과 같은 일부 공정에서 낮은 분산은 높은 정밀도와 관련이 있습니다. 높은 분산은 낮은 정밀도와 관련이 있습니다.
조치의 분산:예
자의 말을했다 비교하는 조치의 분산을 위해 두 개의 데이터 세트입니다. 데이터 세트 A 에는 97,98,99,100,101,102,103 항목이 있고 데이터 세트 B 에는 70,80,90,100,110,120,130 항목이 있습니다. 하여 데이터를 설정할 수 있다는 것을 알 수단 및 중앙값과 동일(100)는 기술적으로는”이라는 측정의 중심 경향”에서 통계입니다.,
그러나,범위(을 제공하는 당신의 아이디어는 어떻게 전파 전체 세트의 데이터가)훨씬 큰 위한 데이터 B(60)할 때에 비해 데이터 설정(6). 사실에서,거의 모든 조치를 분산의 것 열간 더 중대한 데이터에 대한 설정을 만드는 B 의미로 범위가 십 배 더 크다. 예를 들어 두 데이터 세트의 표준 편차를 살펴보십시오.
A 의 표준 편차:2.160246899469287.
B 의 표준 편차:21.602468994692867.
데이터 세트 B 의 수치는 A 의 정확히 10 배입니다.,
경고:사용하는 경우 계산기(또는 수식)확인을 사용하고 있는지 확인하십시오의 올바른 설정(또는 수식)데이터를 보관할 수 있습니다. 분산의 많은 측정(분산과 같은)에는 모집단에 대한 수식과 표본에 대한 수식이 두 가지 있습니다. 표본이나 모집단이 있는지 확실하지 않은 경우 다음 기사를 읽으십시오.
통계에서 모집단은 무엇입니까?
통계의 샘플:그것이 무엇인지,그것을 찾는 방법.
통계 YouTube 채널을 확인하십시오., 기본 통계 주제의 배열에 대한 기본 비디오의 수백.
——————————————————————————
도움이 필요한 숙제 또는 테스트는 질문? Chegg Study 를 사용하면 해당 분야의 전문가로부터 질문에 대한 단계별 솔루션을 얻을 수 있습니다. 체그 교사와 처음 30 분은 무료입니다!