Dyspersja / miary dyspersji: definicja
definicje statystyczne>Dyspersja
Co to jest Dyspersja?
Dyspersja w statystyce to sposób opisania rozproszenia zbioru danych. Gdy zestaw danych ma dużą wartość, wartości w zestawie są szeroko rozproszone; gdy jest mały, elementy w zestawie są ściśle klastrowane., Zasadniczo ten zbiór danych ma małą wartość:
1, 2, 2, 3, 3, 4
…a ten zestaw ma szerszy:
0, 1, 20, 30, 40, 100
rozrzut zbioru danych może być opisany za pomocą zakresu statystyk opisowych, w tym wariancji, odchylenia standardowego i przedziału międzykwartylowego. Spread może być również pokazany na wykresach: działki punktowe, boxplots i działki łodygi i liści mają większą odległość z próbek, które mają większą dyspersję i vice versa.
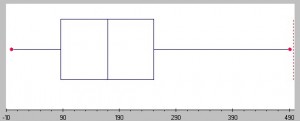
im większe pudełko, tym większe rozproszenie w zestawie danych., Image: Seton Hall University
- Współczynnik dyspersji: termin „catch-all” dla różnych formuł, w tym odległości między kwartylami.
- odchylenie standardowe: prawdopodobnie najczęstsza miara. Mówi ci, jak rozkładane są liczby ze średniej,
- indeks dyspersji: miara dyspersji powszechnie używana ze zmiennymi nominalnymi.
- Interquartile range (IQR): opisuje, gdzie znajduje się większość danych („Środkowa pięćdziesiątka” procent).,
- Interdecile range: różnica między pierwszym decylem (10%) i ostatnim decylem (90%).
- zakres: różnica między najmniejszą i największą liczbą w zbiorze danych.
- średnia różnica lub różnica w średniej: mierzy bezwzględną różnicę między średnią wartością w dwóch różnych grupach w badaniach klinicznych.
- Mediana odchylenia bezwzględnego (MAD): mediana bezwzględnych odchyleń od mediany zestawu danych.
- kwartyle: liczby, które dzielą dane na cztery kwartały (pierwszy, drugi, trzeci i czwarty kwartyle).,
w niektórych procesach, takich jak produkcja lub pomiar, niska dyspersja wiąże się z wysoką precyzją. Wysoka dyspersja wiąże się z niską precyzją.
miary dyspersji: przykład
Załóżmy, że poproszono Cię o porównanie miar dyspersji dla dwóch zestawów danych. Zbiór danych A ma pozycje 97,98,99,100,101,102,103, a zbiór danych B ma pozycje 70,80,90,100,110,120,130. Patrząc na zbiory danych można prawdopodobnie powiedzieć, że środki i mediany są takie same (100), które technicznie nazywane są „Miary tendencji centralnej” w statystyce.,
jednak zakres (który daje wyobrażenie o rozłożeniu całego zbioru danych) jest znacznie większy dla zbioru danych B (60) w porównaniu do zbioru danych A (6). W rzeczywistości prawie wszystkie miary dyspersji byłyby dziesięć razy większe dla zestawu danych B, co ma sens, ponieważ zakres jest dziesięć razy większy. Na przykład, spójrz na odchylenia standardowe dla dwóch zestawów danych:
odchylenie standardowe dla A: 2.160246899469287.
odchylenie standardowe dla B: 21.602468994692867.
Liczba dla zbioru danych B jest dokładnie dziesięciokrotnie większa od A.,
Ostrzeżenie: podczas korzystania z kalkulatora (lub formuły), sprawdź, czy używasz prawidłowego ustawienia (lub formuły) dla danych. Wiele miar dyspersji (jak wariancja) ma dwa różne wzory, jeden dla populacji i jeden dla próbki. Jeśli nie jesteś pewien, czy masz próbkę lub populację, przeczytaj te artykuły:
czym jest populacja w statystykach?
przykład w statystyce: Co to jest, jak go znaleźć.
sprawdź nasz kanał statystyk na YouTube., Setki podstawowych filmów dla szeregu podstawowych tematów statystycznych.
> ——————————————————————————
potrzebujesz pomocy w zadaniu domowym lub pytaniu testowym? Dzięki badaniu Chegg możesz uzyskać krok po kroku rozwiązania swoich pytań od eksperta w tej dziedzinie. Twoje pierwsze 30 minut z korepetytorem Chegg jest bezpłatne!