Dispersion / mått på Dispersion: Definition
Statistikdefinitioner> Dispersion
Vad är Dispersion?
spridning i statistik är ett sätt att beskriva hur spridning av en uppsättning data är. När en datamängd har ett stort värde är värdena i uppsättningen allmänt spridda; när den är liten är objekten i uppsättningen tätt grupperade., Mycket i grunden har denna uppsättning data ett litet värde:
1, 2, 2, 3, 3, 4
…och denna uppsättning har en bredare:
0, 1, 20, 30, 40, 100
spridningen av en datamängd kan beskrivas med en rad beskrivande statistik inklusive varians, standardavvikelse och interkvartilsintervall. Spridning kan också visas i diagram: punkt tomter, boxplots och stam-och blad tomter har ett större avstånd med prover som har en större dispersion och vice versa.
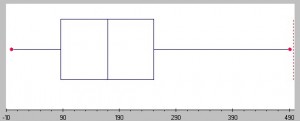
ju större rutan, desto mer spridning i en uppsättning data., Bild: Seton Hall University
mått på spridning.
- Dispersionskoefficient: en ”catch-all” term för en mängd olika formler, inklusive avstånd mellan kvartiler.
- standardavvikelse: förmodligen den vanligaste åtgärden. Det berättar hur utspridda siffror är från medelvärdet,
- Index för Dispersion: ett mått på dispersion som vanligtvis används med nominella variabler.
- Interquartile range (IQR): beskriver var huvuddelen av uppgifterna ligger (”mitten femtio” procent).,
- Interdecile range: skillnaden mellan den första decilen (10%) och den sista decilen (90%).
- intervall : skillnaden mellan det minsta och största antalet i en uppsättning data.
- genomsnittlig skillnad eller skillnad i medel: mäter den absoluta skillnaden mellan medelvärdet i två olika grupper i kliniska prövningar.
- median absolut avvikelse (MAD): medianen för de absoluta avvikelserna från en datamängd median.
- kvartiler: siffror som delar upp uppgifterna i fyra fjärdedelar (första, andra, tredje och fjärde kvartiler).,
i vissa processer, som tillverkning eller mätning, är låg dispersion associerad med hög precision. Hög dispersion är förknippad med låg precision.
mått på spridning: exempel
låt oss säga att du blev ombedd att jämföra mått på spridning för två datamängder. Datamängd A har objekten 97,98,99,100,101,102,103 och datamängd B har objekt 70,80,90,100,110,120,130. Genom att titta på datauppsättningarna kan du förmodligen berätta att medel och medianer är desamma (100) som tekniskt kallas ”mått av central tendens” i statistiken.,
intervallet (som ger dig en uppfattning om hur utspridda hela uppsättningen data är) är mycket större för datamängd B (60) jämfört med datamängd A (6). Faktum är att nästan alla spridningsåtgärder skulle vara tio gånger större för dataset B, vilket är meningsfullt eftersom intervallet är tio gånger större. Ta till exempel en titt på standardavvikelserna för de två datauppsättningarna:
standardavvikelse för a: 2.160246899469287.
standardavvikelse för B: 21.602468994692867.
siffran för datamängd B är exakt tio gånger den för A.,
varning: när du använder en kalkylator (eller en formel), kontrollera att du använder rätt inställning (eller formel) för dina data. Många dispersionsåtgärder (som variansen) har två olika formler, en för en population och en för ett prov. Om du inte är säker på om du har ett prov eller en population läser du dessa artiklar:
vad är en population i statistiken?
prov i statistik: vad det är, hur man hittar det.
kolla in vår statistik YouTube-kanal., Hundratals grundläggande videor för en rad elementära statistik ämnen.
——————————————————————————
behöver du hjälp med en läxa eller testfråga? Med Chegg Study kan du få steg-för-steg-lösningar på dina frågor från en expert på området. Din första 30 minuter med en Chegg handledare är gratis!